PRESS RELEASE (技術)
2016年11月8日
富士通研究開発中心有限公司
株式会社富士通研究所
人工知能モデルを活用した高精度の手書き文字列認識技術を開発
中国科学院自動化研究所の中国語データベースで最高精度達成
富士通研究開発中心有限公司(注1)(以下、FRDC)と株式会社富士通研究所(注2)(以下、富士通研究所)は、手書き文字列での画像認識において、信頼性の高い認識結果を出力できる人工知能モデルを開発し、中国語の手書き文字列の認識性能において、世界最高精度を達成しました。
深層学習をはじめとする人工知能モデルによる単一の中国語手書き文字認識は、すでに人間の認識能力を超えています(注3)。しかし手書きの文字列に適用した場合、1つの文字の区切りを正しく判別できないことが実用上の大きな課題となっていました。今回、手書き文字列の画像認識において、正しい文字を高信頼度に、文字にならない部分を低信頼度に出力可能な新しい人工知能モデルを開発しました。本モデルの適用により、文字の認識ミスを従来の半分以下に抑えることができ、手書きテキスト電子化入力作業などの効率が大幅に向上します。
なお、本技術は富士通株式会社(以下、富士通)のAI技術「Human Centric AI Zinrai(ジンライ)(以下、Zinrai)」に活用していきます。
なお本技術の詳細については、中国で10月24日(月曜日)に開催された国際会議「The 15th International Conference on Frontiers in Handwriting Recognition(ICFHR-2016)」で発表しました。
開発の背景
文字認識の分野は人工知能の活用による業務の効率化が有望な分野です。富士通研究所は数十年にわたる文字認識に関する研究開発の経験を持ち、日本語の言語処理の分野で機械翻訳など多くの技術的蓄積があります。本技術を応用し、FRDCと富士通研究所は、文字認識に人間の脳の働きを模擬した人工知能技術を活用することで、中国語の手書き単一文字に対する認識において、世界で初めて、人間が識別できる能力に相当する認識率を超えたことを実証しています(注3)。
しかし中国語の文字列は複雑な漢字の連続であり、手書きなど1つの文字の区切りが明確でない場合は、これまで文字認識において正確に把握することが困難でした。
課題
人工知能を活用した従来の手書き文字列の認識は、まず文字の教師サンプルを用いて、人間が認識するときに使われるとされる多数の文字パターンの特徴を学習して記憶します。次に文字列画像を、空白部分を判別することで部首とつくりのように複数領域に分割し、分割した領域が一つの文字を表す場合(図1上列)と、隣り合う領域を組み合わせて1つの文字になる場合(図1下列)に分け、それぞれが単一文字と仮定し、学習に基づく認識アルゴリズムにより、候補となる文字と信頼度を出力します。信頼度が1に近いほど、候補文字に対する信頼が高くなり、最終的に平均信頼度の最も高い組み合わせを順に選択していくことにより文字列の認識結果として出力します(図1下段)。しかし従来技術では部首やつくりなど、文字ではない画像に対しても高い信頼度を出力する場合があり、正しく文字の区切りを判別できない課題がありました。
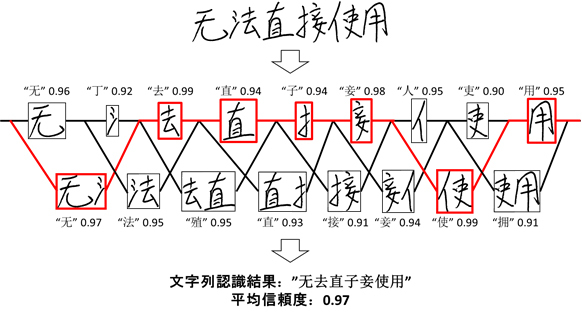
図1:従来深層学習モデルの文字列認識結果
開発した技術
従来の文字の教師サンプルに加え、新たに開発した部首やつくりなどのパーツや、文字にならないパーツの組み合わせからなる非文字の教師サンプルによる異種深層学習モデルにより、正しい文字のみに高い信頼度が出力される技術を開発しました。本技術の特徴は以下のとおりです。
- 非文字を含む異種深層学習モデルの効果的な学習技術
異種深層学習モデルには、従来の文字の教師サンプルと、非文字の教師サンプルの二種類が含まれます。文字の教師サンプルの数と比較して、文字を分解し、さらに組み合わせで得られる非文字の教師サンプルは膨大な数になります。そのため、中国語文中で、隣り合って現れやすいパーツの組み合わせを、非文字の特徴として記憶させて重みづけを行うことで、非対称な構造の深層学習モデルに対しても、効果的に学習できる技術を開発しました(図2a)。
- 信頼度の高低を利用して手書き文字列を正しい区切りで分解する技術
学習済みの異種深層学習モデルに候補領域の画像を入力すると文字と非文字それぞれの信頼度が出力され、文字となる候補領域に高い信頼度を、文字ではない候補領域に低い信頼度を出力する仕組みを設けることにより、文字列中の一つ一つの文字の区切りを効果的に判別する技術を開発しました(図2b)。加えてに既存技術である中国語の言語処理モデルを適用して、認識候補が正しい中国語の文字列になるかということを解析した上で、最終的な候補文章を出力させます。
今回の認識技術を適用すると、文字として存在しないパーツの組み合わせに対しては、文字としてみたときの信頼度のレベルが低くなるため、文字列の先頭から信頼度の高い区切りを順に選択していくことにより正しい認識結果が得られます(図3)。
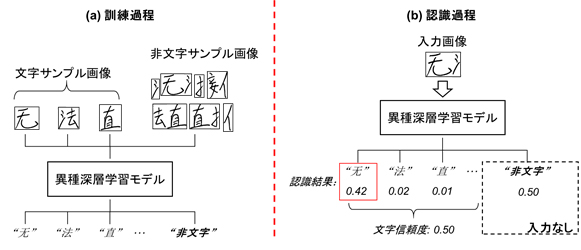
図2 異種深層学習モデルの訓練と認識処理
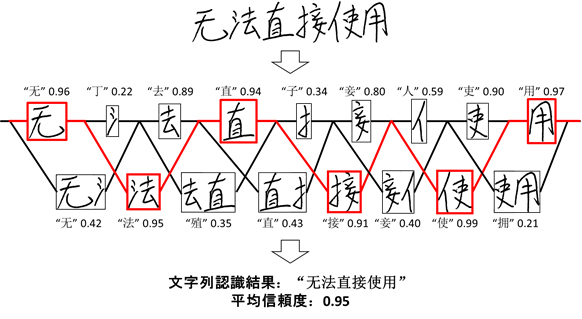
図3 異種深層学習モデルの文字列認識結果
効果
開発した技術を、中国科学院自動化研究所「Institute of Automation, Chinese Academy of Sciences(CASIA)」 が2010年に公開し、学会で標準として用いられている手書き中国語データベースに適用したベンチマークにおいて、従来技術に比べて5%上回る96.3%の最高精度を達成しました。これにより手書きテキスト入力作業などの効率が大幅に向上できます。
今後
本技術は、スペースによる単語の区切りのない、中国語、日本語、韓国語などの言語に対して有効です。本技術を、富士通研究所が長年の技術的蓄積で強みをもつ日本語の言語処理技術と融合させることで、日本語の自由手書き文字に対しても認識精度の大きな向上が見込まれます。本技術は2017年に、富士通のAI技術「Zinrai」への活用を目指し、順次日本向けの手書き帳票電子化などのソリューションに適用していきます。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
- 注1 富士通研究開発中心有限公司:
- 本拠地 中国北京、董事長 佐々木繁。
- 注2 株式会社富士通研究所:
- 本社 神奈川県川崎市、代表取締役社長 佐々木繁。
- 注3 人間の認識能力を超えています:
- 人間の脳の働きを模した人工知能技術を活用し、中国語の手書き文字認識率96.7パーセントを達成(2015年9月17日プレスリリース)
本件に関するお問い合わせ
株式会社富士通研究所
知識情報処理研究所
![]() 044-754-2328(直通)
044-754-2328(直通)
![]() hndwrt-recog@ml.labs.fujitsu.com
hndwrt-recog@ml.labs.fujitsu.com
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。