PRESS RELEASE (技術)
2015年9月17日
富士通研究開発中心有限公司
株式会社富士通研究所
人間の脳の働きを模した人工知能技術を活用し、
中国語の手書き文字認識率96.7パーセントを達成
学会で提唱された「人の認識率」を上回る精度を、世界で初めて実現
富士通研究開発中心有限公司(注1)(以下、FRDC)と株式会社富士通研究所(注2)(以下、富士通研究所)は、人間の脳の働きを模した人工知能技術を活用し、学会で提唱された人間の識別能力相当の認識率を超える96.7パーセント(%)の手書き文字認識技術を世界で初めて開発しました。
FRDCと富士通研究所はこれまで、文書画像処理分野でトップレベルの国際会議「ICDAR (International Conference on Document Analysis and Recognition)」主催の手書き文字(中国語)認識コンテスト(注3)で1位(認識率94.8%)を獲得するなど業界トップの精度を実現してきましたが、さらに認識精度を高めるためには、文字の変形の多様性を学習する新たな仕組みが必要でした。
今回、人間の脳内を模した文字の特徴を捉える階層的モデルにおいて、認識精度を支配する神経細胞間の結線数を拡大し、文字の変形をきめ細かく学習するために、文字の基本パターンから多種多様な変形パターンを自動生成する技術を開発しました。これにより、手書き文字(中国語)で人間の認識率相当(注4)である96.1%を上回る、96.7%を達成しました。
本技術により、コンピュータへの入力業務や確認作業の自動化が期待されます。
開発の背景
一般に、人間は文字、画像や音声といったメディアを簡単に認識できますが、認識対象の変形、明るさの違いなどのバリエーションの多さや、類似した対象物が存在することもあるためコンピュータでの識別は難しく、人工知能の研究課題の一つになっています。
FRDCと富士通研究所は文字認識の分野において数十年以上の経験を持ち、日本語においては日本国内の金融・保険分野での実用化や、中国政府の国勢調査で手書き中国語の文字認識技術が採用され8億枚の帳票認識に活用されるなど、商用の技術レベルを実現しています。2010年より深層学習(Deep Learning)に基づく人工知能による文字認識の研究を開始しました。2013年には、開発した人工知能による文字認識技術が、文書画像処理分野でトップレベルの国際会議主催の手書き文字(中国語)認識コンテストで1位(認識率94.8%)を獲得するなど、業界トップの精度を実現してきました。
課題
文字認識技術では、人間の脳内の神経細胞を想定した階層的に連なるモデルを用いて、人間が認識するときに使われるとされる多数の文字パターンの特徴を学習して記憶します。文字の画像を入力すると、まず前段の階層で文字の単純な特徴を捉え、次に後段の階層で文字の複雑な特徴を捉えます。このように、文字の識別に有効な特徴の抽出が階層的に自動的に行われ、どの特徴(神経細胞)に反応したか、学習結果が文字ごとに蓄積されます。認識の際は、入力された文字から学習の際と同じように階層的に特徴の抽出が行われ、学習結果を基にどの特徴(神経細胞)に反応したかによって文字が特定され認識結果が出力されます。
認識精度をさらに高めるためには、文字の変形の多様性を学習するための新たな仕組みが必要であり、業界のトップレベルの精度は実現したものの、人間の認識能力相当(認識率96.1%)には到達していませんでした。
開発した技術
今回、想定する階層モデルの神経細胞間をつなぐ結線の数を50倍以上に拡大し、学習する文字の変形パターンを多種多様に自動生成する技術を開発しました。これにより、きめ細かく学習することができ、手書き文字(中国語)で人間の認識率相当の96.1%を超える96.7%を達成しました。開発した技術の特長は以下のとおりです。
1. 階層的モデルの規模の拡大
今回、文字認識の過程で利用する階層モデルの神経細胞間をつなぐ結線に対し、きめ細かく変形を学習できるように結線の数を従来技術(認識率94.8%)の約280万から約1億5千万まで増やすことで認識精度を高めました(図1、図2)。
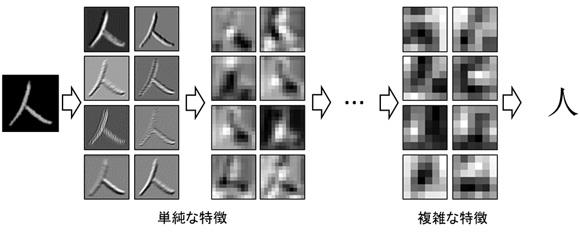
図1 文字認識の過程における各神経細胞間で学習された特徴の可視化
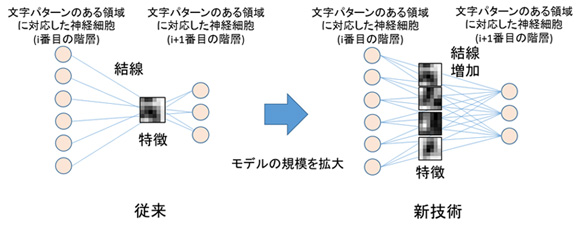
図2 より多くの特徴を捉えるため階層モデルの結線数の拡大
拡大イメージ
{kind=link}
2. 三次元ランダム変形に基づく多種多様な文字サンプル生成
認識対象となる中国語の文字は約3,800種類(注5)あるため、各文字の実際の変形パターンを収集するのは困難です。そこで、既存の文字サンプルをランダムに変形して様々な学習文字サンプルを自動生成する技術を開発しました。これにより、多種多様な変形文字パターンを階層的モデルに学習させることが可能になります(図3)。
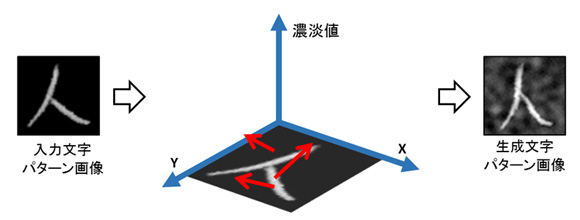
図3 三次元ランダム変形に基づく学習文字サンプル生成
従来手法は、二次元の位置を変形していたため、背景部分と文字の部分(文字線)の明るさの変化や文字線の局所的な変化が困難でした。そこで、三次元のランダム変形に基づく文字サンプル生成技術を考案しました。文字パターン画像上のX座標、Y座標に加え、画素ごとの濃淡値をZ座標のパラメーターとして様々な変形パターンを生成することができます。
効果
開発した技術により手書き文字(中国語)で人間の認識率相当の96.1%を超える96.7%を達成しました。
本技術により、人が行っているコンピュータへの入力業務や確認作業の自動化が期待されます。
今後
FRDCと富士通研究所は、文字認識技術のさらなる高精度化と画像や音声といった文字以外のメディア認識への適用拡大を進めながら、本技術の2015年度中の実用化を目指します。
また、本技術の数字、アルファベット、日本語など多言語の文字認識への適用も併せて検討していきます。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
- 注1 富士通研究開発中心有限公司:
- 本拠地 中国北京、董事長 佐々木繁。
- 注2 株式会社富士通研究所:
- 本社 神奈川県川崎市、代表取締役社長 佐相秀幸。
- 注3 手書き文字(中国語)認識コンテスト:
- 文書画像処理分野の国際会議(ICDAR 2013)主催の手書き文字(中国語)認識コンテスト。
手書き中国語データベース(3755分類、715テストサンプル/分類)を用いて実施。 - 注4 手書き文字(中国語)で人間の認識率相当:
- 文書画像処理分野の国際会議(ICDAR 2013)主催の手書き文字(中国)認識コンテストで提唱された認識率。
- 注5 約3,800種類:
- 中国語の第一水準の漢字が対象。日本語の常用漢字に相当。
本件に関するお問い合わせ
株式会社富士通研究所
知識情報処理研究所
![]() 044-754-2652(直通)
044-754-2652(直通)
![]() big-i-ext@ml.labs.fujitsu.com
big-i-ext@ml.labs.fujitsu.com
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。