PRESS RELEASE (技術)
2020年12月17日
株式会社富士通研究所
ヒトやモノなどのデータの一つひとつが持つ特徴的な因果関係を発見する技術を開発
個々の患者が持つ特徴的な遺伝子や顧客一人ひとりに適したプロモーション施策の特定に活用
株式会社富士通研究所(注1)(以下、富士通研究所)は、ヒトやモノなどに関する様々なデータの一つひとつが持つ特徴的な因果関係をAIで発見する技術を開発しました。
例えば、医療現場では、患者一人ひとりの発がんに影響を与える特徴的な遺伝子の特定が求められ、またマーケティングの現場では、顧客一人ひとりの購入に繋がる特徴的な要因を見つけることが求められています。今回、データ全体から共通の相関関係をもつデータの集まりを高速にすべて抜き出し、抜き出したデータの集まりそれぞれの因果関係を評価して特徴的な因果関係を見つけることで、一つひとつのデータが持つ特徴的な因果関係を発見する技術を開発しました。本技術を大腸がん患者の遺伝子発現データに適用し、患者一人ひとりのデータに現れる特徴的な因果関係を推定したところ、患者ごとの治療方針立案の鍵となる大腸がん分類で着目すべき遺伝子を再発見することに成功しました。
本技術により、医療やマーケティング以外にも、金融における顧客ごとの与信のスコアリングや、製造における製品ごとの不良原因の特定などが可能となります。
開発の背景
近年、医療やマーケティングなど様々な業務において、実問題解決のためにAIを活用して施策を立案することが増えてきています。解決したい問題の重要な要因を特定し、施策を立案するためには、属性AとBの間に関連があるという相関関係だけでなく、AだからBであるという原因と結果を表した因果関係に注目する必要があります。
これまでデータ全体に対する因果関係を推定する技術は、データ分析の分野での研究により開発されていますが、多くの実問題解決のためには、一つひとつのデータが持つ因果関係を推定することが必要とされています。例えば、医療現場におけるがん治療の場合、多くの患者それぞれにおいて、がんの病態に影響する固有の遺伝子が発現しているので、患者一人ひとりに適切な治療方針を立案するためには、がん患者全員に共通する遺伝子ではなく、がん患者一人ひとりに特徴的な遺伝子を特定することが必要となります。また、マーケティングの現場におけるプロモーションの場合、多くの顧客それぞれが購入につながる異なった特性をもっており、顧客一人ひとりに適切な施策を立案するためには、顧客全員に共通する原因ではなく、顧客一人ひとりの原因を見い出すことが必要になります。
このように、多くの実問題解決のために必要とされる、データの一つひとつが持つ特徴的な因果関係を推定する技術の開発が求められています。
課題
一つひとつのデータに対する特徴的な因果関係を正確に求めるためには、対応するヒトやモノに同じ条件のもとで異なる操作や作用を与えた結果を比較することが必要になります。しかし、一人のがん患者に対して異なる遺伝子を発現させたり、一人の顧客に対して異なるプロモーション施策を実施した結果を得ることは困難です。したがって、異なる複数の患者や顧客のデータ全体から、一つひとつのデータが持つ特徴的な因果関係をどのようにして発見するかが課題となっていました。
開発した技術
今回、一つひとつのデータが持つ特徴的な因果関係の発見が可能な因果探索技術を新たに開発しました。
開発した技術の特長は以下の通りです。
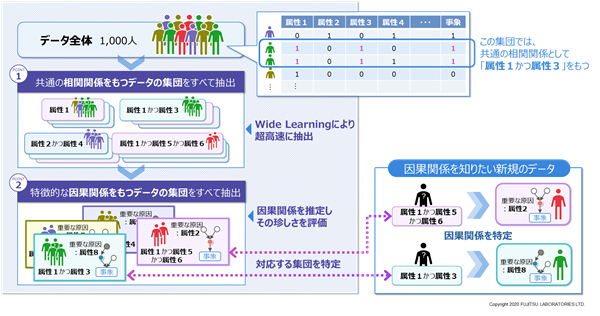
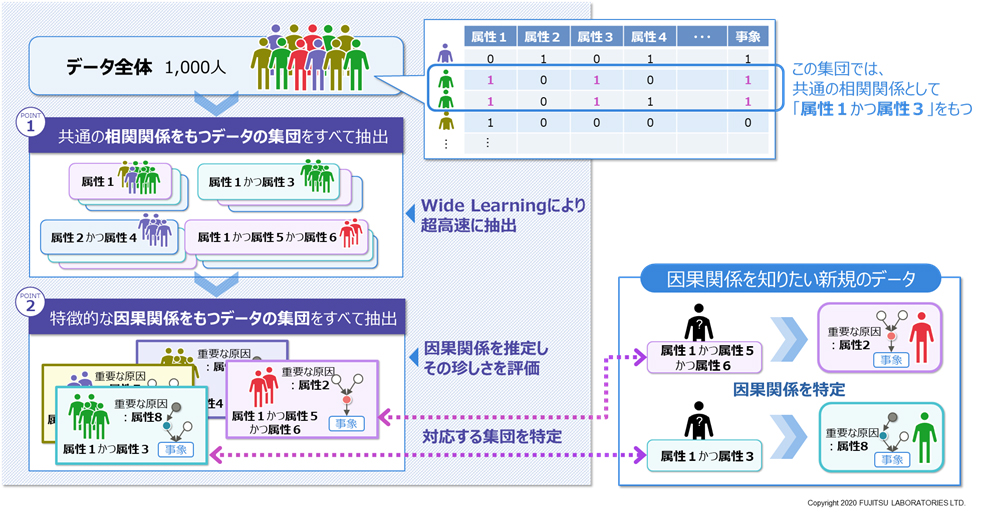
- 共通の相関関係をもつデータの集団をすべて抽出する技術
因果関係よりも緩やかな関係性である相関関係に着目し、共通の相関関係をもつデータの集団をデータ全体からすべて抜き出します。データの属性数が50種類を超えると、相関関係の最大数は1,000兆を超え(注2)ますが、当社が開発した重要な組み合わせを漏れなく超高速に見つける技術「Wide Learning(注3)」を用いることで、データ中のあらゆる相関関係の発見を可能とし、そのようなデータの集団を数秒ですべて抽出することができます。例えば、がん発症の原因を調べる場合、遺伝子の発現の有無を属性として、発現している遺伝子の組み合わせを探索することにより、共通の相関関係をもつ患者の集団を抜き出します。
- 特徴的な因果関係をもつデータの集団をすべて抽出する技術
次に、抜き出したデータの集団に対して因果関係を推定し、それぞれの因果関係における属性の種類や、因果関係の強さ、向きなどを比較します。これにより因果関係の珍しさを定量的に評価し、珍しさのスコアが高いものを特徴的な因果関係として網羅的に発見します。
これら2つの技術により、特徴的な因果関係をもつデータの集団をすべて抽出できるため、因果関係を知りたい新規のデータに当てはまる集団を特定することで、一つひとつのデータの特徴的な因果関係を求めることができます。
開発した技術のイメージ
拡大イメージ
{kind=link}
効果
これまでの遺伝子解析の研究では、大腸がんの中には従来から知られている通常のタイプに加え、免疫反応が強いタイプ、代謝異常があるタイプなど複数の種類があり、それぞれで発現する遺伝子は異なっていることが明らかになっています。
今回、琉球大学(注4)医学部の協力のもと、TCGA(注5)およびGTEx(注6)によって公開されているデータから、約1,000人分の大腸がん組織と通常の大腸組織における遺伝子発現データ(注7)を抽出し、これに本技術を適用させ大腸がんの種類(注8)を区別する際に重要とされている遺伝子を自動で特定できることを確認しました。
琉球大学医学部の高橋健造教授、宮城拓也助教、内海大介助教からは、「本技術は、医療研究者に、発見の具体的な根拠となる因果関係までを含めてフィードバックし、患者一人ひとりの発がん因子の特定を可能とするものです。本技術が、患者一人ひとりに向けた最適な医療の提供につながることを期待します。」との評価をいただいています。
今後
当社は、今後、ゲノム医療分野において一人ひとりの患者に合わせた最適な医療法を選択する個別化医療や、がんの起源の解明など医療研究への貢献を目指して研究を進めます。また、医療分野だけでなく、マーケティング、製造、金融など様々な現場における2020年度中の業務適用や検証を進めるとともに、富士通株式会社(注9)のAI技術「FUJITSU Human Centric AI Zinrai」を支える新たな機械学習技術として2021年度の実用化を目指します。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
- 注1 株式会社富士通研究所:
- 本社 神奈川県川崎市、代表取締役社長 原 裕貴。
- 注2 データの属性数が50種類を超えると、相関関係の最大数は1,000兆を超える:
- 属性1つにつき最低でも2分類あり(遺伝子の発現の「有り」「無し」など)、2を50乗した場合、1,000兆通りを超える。
- 注3 Wide Learning技術:
- 仮説の網羅的な列挙により、判断根拠の説明や知識発見が可能なAI技術。
正解が少ないデータでも高精度に学習するAIの新技術「Wide Learning」を開発(2018年9月19日プレスリリース) - 注4 琉球大学:
- 所在地 沖縄県中頭郡西原町、学長 西田 睦。
- 注5 TCGA:
- The Cancer Genome Atlasの略称。米国がん研究所 (National Cancer Institute: NCI) と、米国ヒトゲノム研究所 (National Human Genome Research Institute: NHGRI) の共同プロジェクト。実証実験では、TCGAの公開する33種類のがん種についてのサンプルの遺伝子発現量データを活用。
- 注6 GTEx:
- 米国ブロード研究所などの複数の研究機関から構成される国際コンソーシアム。実証実験では、GTExの公開するヒトの体組織ごとの遺伝子発現量データを活用。
- 注7 遺伝子発現データ:
- 今回の実証実験を目的に、琉球大学医学部にて各遺伝子の発現量の多い・少ないの基準を判断し独自に作成したデータ。
- 注8 大腸がんの種類:
- 大腸がんについて、2015年に決められた米国と欧州の国際会議での分類。
- 注9 富士通株式会社:
- 本社 東京都港区、代表取締役社長 時田 隆仁。
関連リンク
- Wide Learning公式サイト「Hello, Wide Learning!」
- 東京医科歯科大学と富士通研究所、「富岳」を用いてがんの遺伝子ネットワーク分析を1日以内に実現(2020年11月10日プレスリリース)
- 株式会社富士通研究所
本件に関するお問い合わせ
株式会社富士通研究所
人工知能研究所
![]() 044-754-2328(直通)
044-754-2328(直通)
![]() widelearning@ml.labs.fujitsu.com
widelearning@ml.labs.fujitsu.com
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。