PRESS RELEASE (技術)
2020年11月16日
株式会社富士通研究所
AIによる大量の自動映像監視を実現する映像特徴量の高圧縮技術を開発
ディープラーニングによる画像認識性能を保ったまま圧倒的な高圧縮を実現
株式会社富士通研究所(注1)(以下、富士通研究所)は、超高圧縮した映像からでも高精度に映像の内容を認識できる映像圧縮技術を開発しました。
近年、ディープラーニングによる画像認識の飛躍的な性能向上により、映像から情報を抽出する画像認識AIソリューションが注目され、AI認識に特化した映像圧縮技術の開発が活発化しています。特に、監視・確認作業などをAIによって自動化する場合には画像を復元せずに、AIが画像認識するために必要な深層特徴量のみを圧縮・伝送する技術が注目されています。
今回、当社独自開発の高次元データ解析技術「DeepTwin(ディープツイン)」(注2)を深層特徴量の圧縮に応用し、画像認識精度を低下させることなく、従来のH.265(注3)による映像圧縮とAIを組み合わせた一般的な方式と比較して、100倍以上の圧縮率を達成可能な映像圧縮技術を開発しました。本技術の活用により、画像認識AIソリューションの普及に伴ってますます大容量化する映像伝送データ量の増加を抑制するとともに、限りある通信資源の効率的な利用を実現し、より持続可能な世界の実現に貢献します。
本技術の詳細は、11月16日(月曜日)からオンラインで開催予定の「画像符号化シンポジウム (Picture Coding Symposium of Japan 2020)」にて発表します。
背景
画像圧縮技術は、デジタル化された映像データのDVDやBlu-Ray媒体などへの記録や、インターネット上での映像配信など、限られたデータ領域を効率的に利用するための手段として利用されています。当社は、これまで長年に渡り映像圧縮技術に取り組んでおり、H.264(注3)の標準化および符号化LSIの開発による映像伝送装置の実用化などを進めてきました。
また近年、ディープラーニングの飛躍的な発展により、AIが大量の映像データから情報を引き出すことで、人による監視・確認作業などを自動化する画像認識AIの活用が拡がっています。こうした画像認識AIの発展により、映像圧縮の規格化を行うISO/IEC(国際標準化機構・国際電気標準会議)のワーキンググループであるMPEGにおいても、Video Coding for Machines (VCM) という、機械学習に特化した映像圧縮方式の検討が提案され、AIによる認識性能を劣化させずにデータ量を軽減するための圧縮技術の開発が求められています。
課題
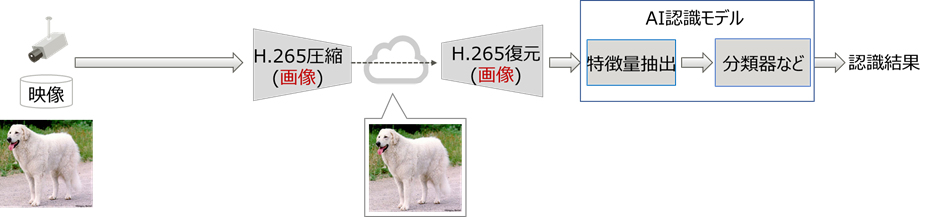
これまでの画像認識AIを使ったアプリケーションでは、映像をH.265などの映像圧縮技術で圧縮して伝送し、受信側で復元された映像をAI認識モデルとして入力し認識を行うのが一般的です(図1(a))。一方、画像認識AI向けの映像圧縮技術では、AI認識モデルを特徴量抽出部と分類や物体検出などを行う部分とに分離し、映像データを特徴量抽出部に入力して得られる深層特徴量データを圧縮して伝送し、受信側で復元処理した後に分類器などでの画像認識を行います(図1(b))。この深層特徴量の圧縮の部分、すなわち特徴量圧縮技術には、様々な手法が提案されていますが、今後、さらなる増大が想定される高精細な映像データの需要を満たすには、既存の映像圧縮技術であるH.265より高い圧縮性能を持った特徴量圧縮技術の開発が課題となっています。
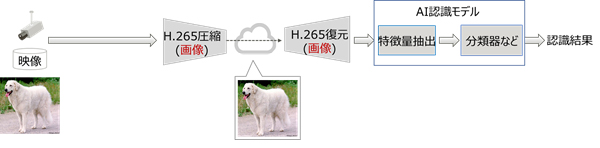
(a) 従来のH.265を用いた画像ベースAI認識のフレームワーク
拡大イメージ
{kind=link}
(b) AI認識に特化した特徴量圧縮のフレームワーク
拡大イメージ
{kind=link}
図1 画像認識のフレームワーク
開発した技術
今回、当社が独自開発した、高次元データの分布・確率などの本質的な特徴量を正確に獲得するAI技術「DeepTwin」を特徴量圧縮に適用することで、認識率の劣化を一定値に抑えながら、圧倒的な圧縮効率を達成できました。
開発した技術の特長は以下の通りです。
AI認識に必要な最小限のデータ量まで圧縮する映像圧縮技術
「DeepTwin」のオートエンコーダ(注4)は、データの評価尺度を定めると、その評価尺度の値を保ったままデータの情報量が最小となるよう次元圧縮できることが理論的に保証されています。今回、この評価尺度を一般的な特徴量圧縮手法が注目する圧縮前後の特徴量の復元誤差ではなく、画像認識AIの認識率として定めました。これにより、認識率に必要な次元以外が削減されるようにオートエンコーダが学習され、認識率を維持したまま従来の画像ベース方式を大きく超える深層特徴量圧縮性能を可能としました(図2)。
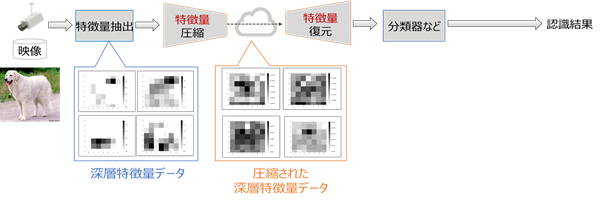
また、「DeepTwin」で圧縮された後の特徴量が持つ情報量を調べると、一部に大きく偏った分布となります(図3)。これは、圧縮後の特徴量では、一部に必要な情報が凝縮されていることを意味しています。そのため、圧縮後の特徴量のうち、情報量が低く、認識率への影響が小さいデータから段階的に削減するように加工すれば、必要な認識率に応じてデータ量を制御することができます。
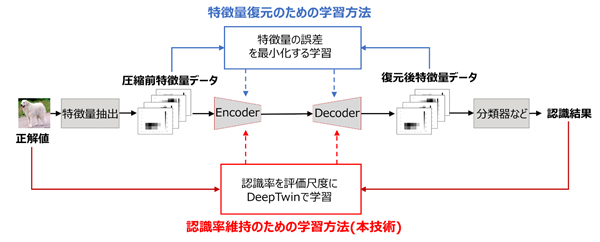
図2 特徴量復元のための学習方法(青)と、本技術によるオートエンコーダの学習方法(赤)
拡大イメージ
{kind=link}
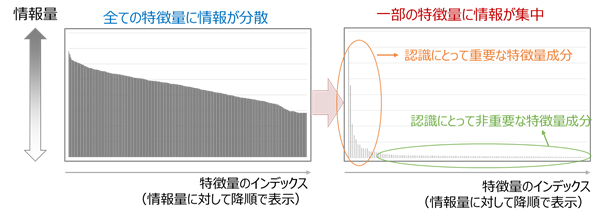
図3 圧縮前後の特徴量の情報量の特性
拡大イメージ
{kind=link}
効果
今回開発した技術を用いることで、AIによる画像認識性能の劣化を一定に抑えながら、従来方式を大きく超える高圧縮を行うことができます。具体的には、AI認識モデルの一種であるVGG16(注5)を用い、映像に映っている物体を汎用的な用途として100カテゴリに分類するタスクに対して本技術を適用した場合、非圧縮の認識率から5%劣化するときの、H.265を用いた画像ベースの方法と比較して、100倍の圧縮性能を達成できました(図4)。また、例えば自動車やトラック、オートバイといった車両の分類など特定用途を想定して20カテゴリに分類する場合には、300倍の圧縮性能となり、いずれの認識劣化量の場合においてもH.265ベースの方式と比較して高い圧縮性能を達成できました。
本技術を活用することで、今後の画像認識AIソリューションの発展によるデータ量増加を抑制し、限りある通信資源の効率的な利用を可能とし、より持続可能な社会の実現に貢献します。
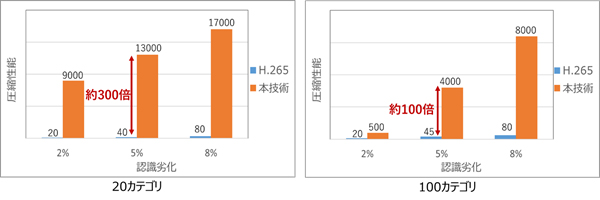
図4 画像認識AIモデルとしてVGG16を用いた場合のH.265と本技術の圧縮性能の比較
拡大イメージ
{kind=link}
今後
当社は、2021年度中の実用化に向けて、特徴量圧縮率のさらなる向上、およびディープラーニングによる画像認識の適用範囲拡大を目指して開発するとともに、今後、通信インフラの拡充や自動化のニーズを背景に発展するAIによる映像利活用を支援していきます。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
- 注1 株式会社富士通研究所:
- 本社 神奈川県川崎市、代表取締役社長 原裕貴。
- 注2 当社独自開発の高次元データ解析技術「DeepTwin(ディープツイン)」:
- 高次元データの分布・確率などの本質的な特徴量を正確に獲得するAI技術。
世界初!教師データなしで高次元データの特徴を正確に獲得できるAI技術を開発(2020年7月13日プレスリリース) - 注3 H.265, H.264:
- 画像圧縮方式の一つ。ITU-T(国際電気通信連合・電気通信標準化セクタ)とISO/IEC(国際標準化機構・国際電気標準会議)が共同で策定した、映像圧縮の国際標準規格。
- 注4 オートエンコーダ:
- ニューラルネットワークの一種で、入力と出力が同じになるようにニューラルネットワークを学習させることで次元圧縮を行う手法。
- 注5 VGG16:
- 画像分類に用いられる畳み込みニューラルネットワークモデルの一種。
関連リンク
本件に関するお問い合わせ
株式会社富士通研究所
デジタル革新コア・ユニット
![]() 044-754-2533(直通)
044-754-2533(直通)
![]() labs-feature-comp@dl.jp.fujitsu.com
labs-feature-comp@dl.jp.fujitsu.com
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。