PRESS RELEASE (技術)
2019年10月16日
株式会社富士通研究所
暗号化した機密情報の類推を防止する技術を開発
クラウド環境など様々な場所で管理されるデータベースをより安心して使うことが可能に
株式会社富士通研究所(注1)(以下、富士通研究所)は、データベースと検索内容を暗号化したまま照合できる秘匿検索技術を強化し、暗号化されたデータベースから元データの類推を防止することで、より安全に照合できる技術を開発しました。
暗号化されたデータベースでも、公開された統計情報などと比較することで、登録数の一致などから元データを推定される危険性があります。今回開発した技術は、データベースに最小限のダミーデータを追加することで、データベース上の登録数を攪乱し、元データの類推を防止することができます。
これにより、クラウド上など様々な場所で管理される、パーソナルデータ(注2)や機密データ(注3)を暗号化させたデータベースを、さらに安全に活用することが可能になり、組織を横断したデータ利活用の促進が期待されます。
開発の背景
官民データ活用推進基本法(注4)の施行などの法整備、クラウド利用やビッグデータ分析などのシステム普及に伴い、パーソナルデータや機密データを組織や異業種間で横断して活用することが期待されています。医療分野では、2018年に次世代医療基盤法(注5)が施行され、病院での診療データにもとづいて、企業や大学による研究開発や創薬などが進められています。
パーソナルデータや機密データを安全に扱うために、データベースに登録するデータと利用者側が入力する検索文字列を、暗号化したまま照合できる秘匿検索技術があります(図1)。これにより、鍵を持つ利用者だけが検索文字列に対応したデータベースの登録数を参照することが可能となります。
しかし、例えば医療分野では、公的機関や医療機関が公開している病名や医薬品などの統計情報と、データベースに登録されている件数を突き合わせることで、暗号化したデータベースであっても、そのデータの内容を類推できてしまう問題がありました。さらに、データベースの内容が類推できてしまうと、検索文字列が暗号化されていても、検索結果から利用者が何を検索したのかも推定できてしまいます。データ提供者および利用者にとって、クラウドなど様々な場所で管理されるデータベースをより安心して使えるようにする必要があります。
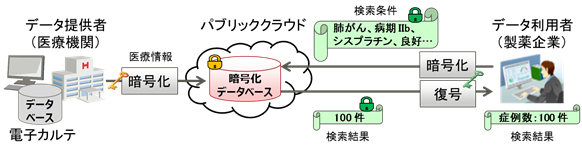
図1. 従来の秘匿検索技術による医療データの利活用イメージ
拡大イメージ
{kind=link}
課題
暗号化されたデータベースや検索文字列の元データを類推できる問題への対策として、データベースにダミーデータを追加する方法があります。これにより、データベースに登録されているデータの真の件数が把握できないため、元データを類推できなくなります。しかし、一般的なダミーデータの追加方法は、もっとも件数が多い項目にあわせる形でほかの項目に対してダミーデータを追加していくため、最大件数とデータの種類に応じて、データベースに登録されるデータ量が数百倍以上に増加してしまい、実用的ではありませんでした。
開発した技術
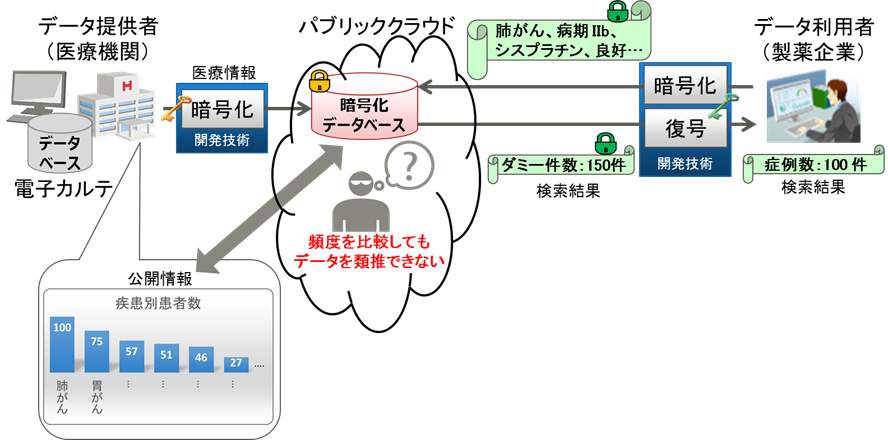
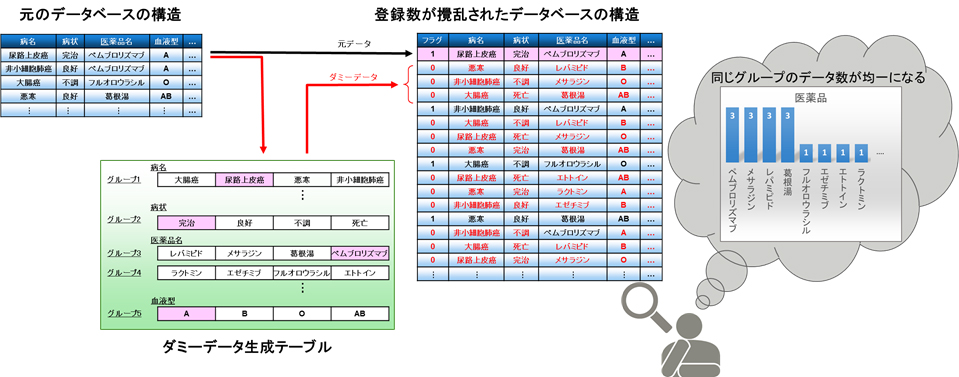
今回、秘匿検索技術を拡張し、実用的なデータ量の増加で、安全に照合できる技術を開発しました(図2)。これにより、統計情報との突き合わせや検索文字列の類推を防止し、データベースの安全性を強化できます。開発技術の特長は以下のとおりです。
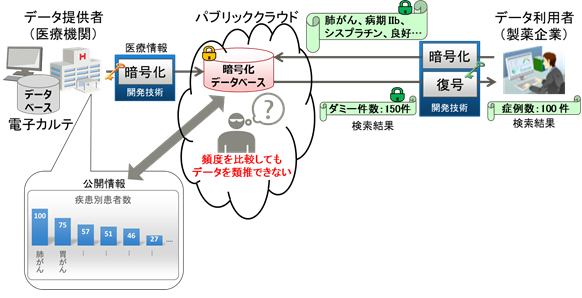
図2. 開発したデータの類推を防止する技術
拡大イメージ
{kind=link}
- データベースからの類推を防止し安全性強化
例えば、病名、医薬品、血液型といったデータの項目ごとにグループを作り、そのグループごとにダミーデータを入れていきます。各グループ(例::血液型)の要素(例:A型、B型、O型、AB型)の数がそれぞれ均一になるようにダミーデータを登録していくことで、それぞれの要素がデータベース上ではすべて同じ数で出現し、類推をすることができなくなります(図3)。
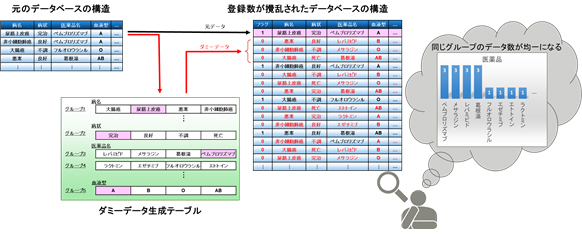
図3. 登録数が攪乱されたデータベースの構造
拡大イメージ - データ量増加を抑制
グループ内の要素の数が均一になるように、グループごとに最小限の数のダミーデータが作成されるため、データ量の増加を抑えることができます。なお、検索結果に含まれるダミーデータの件数は、独自のルールで作成されたフラグを照合することで容易に除外できるため、利用者には処理された後の正しい検索結果が提供されます。
{kind=link}
効果
本技術を活用し、2,000項目からなる診察記録10億件(注6)をデータベースに登録したところ、データ量の増加を元データの9倍以内に抑え、統計情報と登録数が一致せず類推できない状態で照合ができることを確認しました。本技術を医療分野に活用することで、電子カルテなど機密情報をクラウド上で共有し、登録情報や検索内容を秘匿したまま、製薬会社がデータベースでの登録数を安心して照合できるため、新薬開発の効率向上が期待できます。
また、本技術は、医療分野に限らず、公共分野におけるデータを基にした自治体の街づくりや、金融分野の顧客データのマーケティングなどに応用できます。
今後
今後、データの匿名化技術やプライバシーリスクの評価技術など、富士通株式会社や富士通研究所のセキュリティー技術と組み合わせて提供していくことを検討していきます。まずは、医療分野においてデータ利活用の実証実験から検証を進め、2020年度までに医療情報のデータ利活用ソリューションの実用化を目指します。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
- 注1 株式会社富士通研究所:
- 本社 神奈川県川崎市、代表取締役社長 原 裕貴
- 注2 パーソナルデータ:
- 個人に関する情報全般。例えば、個人を特定、識別することができる氏名、生年月日、住所や、いくつかの情報と容易に照合することで個人を特定できる個人の位置情報や購入情報、購買履歴、ウェアラブル機器から収集された情報など。
- 注3 機密データ:
- 企業が開示を予定していない重要な情報。例えば、研究報告書、企画書、顧客情報、給与情報、人事異動に関する情報など。
- 注4 官民データ活用推進基本法:
- 国、自治体、独立行政法人、民間事業者などが管理するデータを活用した新ビジネスの創出や、データに基づく行政、医療介護、教育などの効率化ができるようにする法律。2016年12月施行。
- 注5 次世代医療基盤法:
- 患者の経過記録や検査データなど医療機関などが持つ患者の医療情報を匿名加工し、大学や企業が研究開発に活用できるようにするための法律。2018年5月施行。
- 注6 2,000項目からなる診察記録10億件
- 2014年度に入院患者に投与された内服薬の公開された統計情報をもとにした総数量。
本件に関するお問い合わせ
株式会社富士通研究所
デジタル革新コア・ユニット
![]() 044-754-2668(直通)
044-754-2668(直通)
![]() encrypted-search@ml.labs.fujitsu.com
encrypted-search@ml.labs.fujitsu.com
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。