PRESS RELEASE (技術)
2018年9月20日
株式会社富士通研究所
分散ストレージ上で大量データを高速処理する基盤技術を開発
システム全体のパフォーマンスを向上し、分散ストレージの利用用途を拡大
株式会社富士通研究所(注1)(以下、富士通研究所)は、増え続ける大量データの処理を高速に行うために、分散ストレージシステム上で大容量蓄積と高速データ処理を両立させる技術を開発しました。
昨今、急速に大容量化が進んでいる映像やログデータといった非構造化データを含む大量のデータを、AIや機械学習などで分析して利活用するニーズにおいて、データを蓄積しているストレージシステム上で分析まで行うことでデータ処理速度を向上することが期待されています。しかし、一方で、分散して蓄積されている非構造化データの効率的な分析や、本来のデータ管理のためのストレージ機能とデータ処理との両立が必要です。
今回、大量データの高速処理を行うために、データを蓄積している分散ストレージシステム上で、本来のストレージ機能を動かしつつデータ処理を行う技術「Dataffinic Computing(データフィニックコンピューティング)」を開発しました。本技術により、非構造化データを含む大量データの高速処理を可能とし、監視カメラ映像利活用、ICTシステムのログ分析、車のセンサーデータ利活用、ゲノムデータ分析といった増え続けるデータの効率的な利活用を実現します。
開発の背景
近年、様々な現場で発生する大量データを利活用することで、ビジネスの革新や新たなイノベーションの創出を行う動きが本格化してきています。従来の顧客データやPOSデータといったデータベースで管理してきた構造化データだけでなく、映像やログデータといった爆発的に増加している非構造化データも含めた大量のデータを効率的に利活用するために、AIや機械学習などで効率的に分析することが求められています。従来、データは処理サーバで分析されてきましたが、データを蓄積しているストレージシステム上で分析することができれば、データ処理の高速化が図れると期待されています。
課題
通常のデータ処理では、ストレージシステムに蓄積されているデータを処理サーバに読み出す必要があります。ストレージシステムと処理サーバの間を流れるデータ量が増加することで、データの読み出しに要する時間が大量データ利活用におけるボトルネックとなっています。その一方で、ストレージシステム上でデータを移動させずに処理することで高速処理が可能になりますが、分散して蓄積された非構造化データの分析や、本来のストレージ機能と処理機能との両立を行う必要があります。
開発した技術
増え続ける大量データを高速に処理するために、複数のサーバをネットワークで接続しデータを分散して蓄積する分散ストレージシステムにおいて、本来のストレージ機能の性能を低下させることなくデータ処理を行う技術「Dataffinic computing」を開発しました。
開発した技術の特長は以下のとおりです。
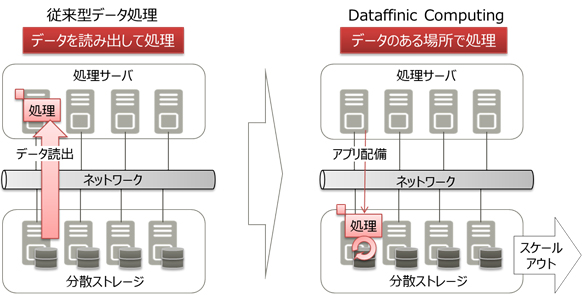
図1. 「Dataffinic Computing」でのデータ処理イメージ
- 分散したデータごとに処理可能なコンテンツアウェアデータ配置
分散ストレージシステムでは、アクセス性能を出すために、大容量データを同じ箇所に保存せず、ストレージシステムが管理しやすい容量ごとにデータを分割させて格納します。しかし、映像やログデータなどの非構造化データの場合は、決められた容量ごとに規則的に分割すると、それぞれに格納した各断片データだけでは不完全で処理できないため、分散されたデータを一度集めたうえで処理する必要があり、システム上の大きな負荷となっていました。今回、非構造化データを、データの関連性の切れ目で分割することで、断片データだけでも処理可能なデータとして蓄積します。また、処理に必要となる情報(ヘッダ情報など)を、断片のデータごとに付与情報として持たせます。これにより、それぞれの分散ストレージ上で蓄積された断片データごとの処理が可能となり、アクセス性能のスケーラビリティを維持しつつ、システム全体のパフォーマンスを向上させます。
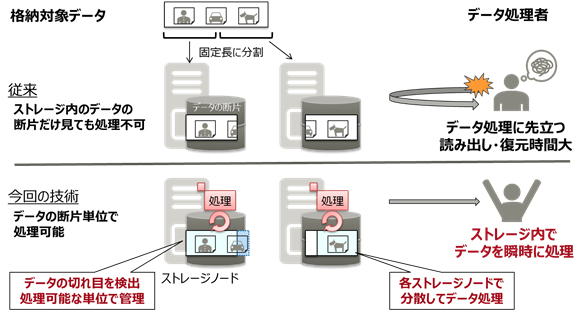
図2. 非構造化データの格納・処理イメージ - ストレージ機能とデータ処理を両立するアダプティブリソース制御
ストレージノードでは、通常のデータ読み書きに加え、故障時の自動復旧処理や、容量追加時のデータ再配置処理、予防保守を目的としたディスクチェック処理といった、データを安全に保管するための様々なシステム負荷が発生しています。それらのストレージシステム内部で発生するシステム負荷をモデル化して、近い将来に必要とするリソースを予測し、それを基にストレージ機能の性能を低下させないようにデータ処理の使用リソースと配備先を制御します。これにより、本来のストレージ機能の安定稼働を実現した上で、高速データ処理を可能とします。
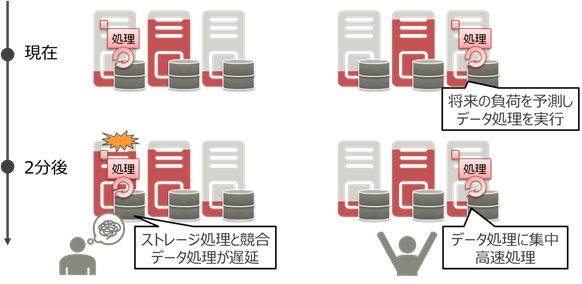
図3. 必要リソースの予測とデータ処理のためのリソース制御のイメージ
効果
本技術をオープンソースソフトウェアの分散ストレージソフトウェア「Ceph(セフ)(注2)」上に実装して効果の検証を行いました。5台のストレージノードと5台の処理サーバとの間を1Gbpsのネットワークで接続して、50GBの映像データの中に含まれる人や車などのオブジェクトを抽出するデータ処理性能を測定しました。従来方式では処理が完了するまでに500秒要していましたが、開発した技術を用いることで、従来比10倍の速度となる50秒での処理が完了することを確認しました。
本技術により、増え続けるデータに対してスケーラブルなデータ処理を可能とし、爆発的に増大するデータの効率的な利活用への適用が期待できます。
今後
富士通研究所では、本技術の業務適用を想定した検証を進め、2019年度中に富士通株式会社での製品化を予定しています。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
- 注1 株式会社富士通研究所:
- 本社 神奈川県川崎市、代表取締役社長 佐々木繁。
- 注2 Ceph:
- 2004年以前にカリフォルニア大学で開発が開始されたCephコミュニティーが管理しているオープンソースソフトウェアの分散ストレージソフトウェア。
本件に関するお問い合わせ
株式会社富士通研究所
コンピュータシステム研究所
![]() 044-754-2632(直通)
044-754-2632(直通)
![]() dataffinic@ml.labs.fujitsu.com
dataffinic@ml.labs.fujitsu.com
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。