PRESS RELEASE (技術)
2016年7月19日
株式会社富士通研究所
業界初!パーソナルデータのプライバシーリスクを自動評価する技術を開発
改正個人情報保護法における匿名加工データ連携を加速
株式会社富士通研究所(注1)(以下 富士通研究所)は、業界で初めてパーソナルデータに関するプライバシーリスクの自動評価技術を開発しました。2017年中に施行予定の改正個人情報保護法では、本人同意がなくとも匿名加工によりパーソナルデータの第三者提供が可能になります。匿名加工データの提供にあたっては、提供元が事前にガイドラインとの適合や個人特定リスク評価を行う必要があり、国外の事例では専門家による審査に多くの日数を必要とするケースもありました。
このため富士通研究所は、パーソナルデータを元に個人特定リスクを自動評価する技術を業界で初めて開発しました。これにより、複数の組織間での安全なデータ連携をスピーディーに行うことが可能になり、様々な分野でサービス・製品の品質向上や、異業種の共創による社会問題の解決につなげることが期待できます。
本技術の詳細は、7月14日(木曜日)から7月15日(金曜日)まで山口県で開催された、情報処理学会「コンピュータセキュリティ研究会(CSEC研究会)」にて発表しました。
開発の背景
2017年中に施行予定の改正個人情報保護法では、パーソナルデータに匿名加工を行うことで本人の同意なく第三者提供が可能となります。これにより、異なる組織でデータを安全に利活用できるようになり、新しいサービス・製品の品質向上につなげたり、組織が連携することで共創や社会問題の解決につなげることが期待されます。匿名加工には様々な匿名化手法が存在し、分野やガイドラインによって使い分けが必要となります。
例えば、医療分野において、改正個人情報保護法に基づいてガイドラインが策定された場合、医療機関で保有する健診データなどを、匿名加工して研究機関や製薬会社などで活用するといったことも考えられます(図1)。そのため、富士通研究所では、k-匿名化という、同じ属性を持つ人が少なくともk人以上いるように情報を加工する技術を中心とする匿名化技術を開発し、医療分野などへの適用に向けて研究を進めてきました。
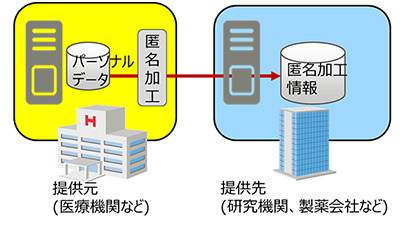
図1 改正個人情報保護法における匿名加工情報の第三者による利活用イメージ
課題
パーソナルデータの提供元は、匿名加工を行うにあたり、業界ごとのガイドラインを満たしているか、匿名加工されたデータからプライバシーが漏えいしないかなどのリスクに備える必要があります。しかし、提供元が匿名加工データから個人を特定されるリスクを評価し対策することは容易ではなく、従来は専門家による確認、評価に時間がかかっていたことが課題でした。例えば、医療機関が持つデータを、匿名化して医療研究に利用するケースにおいて、国外の医療機関ではデータが提供できるまで半年以上かかるケースも報告されています。
そのため富士通研究所は、匿名加工データから個人が特定されるリスクの評価と対策をスピーディーに実行するためには、最も個人を特定しやすい属性を探索したうえで、適切な匿名化手法を適用することが重要であると考えました。しかし、個人の特定は多数の属性(性別、電話番号、住所など)の組み合わせによって可能なため(図2)、最も特定しやすい属性の組み合わせの計算は膨大で現実的な時間での探索が困難でした。

図2 一部の属性の組み合わせで個人を特定できる例
拡大イメージ
{kind=link}
開発した技術
今回、データの分布に基づいて、最も個人を特定しやすい属性の組み合わせとその容易度(特定しやすさ)を、現実的な時間内で自動的に探索する技術を業界で初めて開発しました。これにより、データ提供元はリスク評価と対策を迅速に行うことができます。開発した技術の特徴は以下の通りです。
- 個人特定可能な属性の組み合わせを効率的に探索する技術
個人を特定しやすい属性の組み合わせから優先的に評価すべき属性を抽出することで、効率的に探索する技術を開発しました。より少ない属性の組み合わせで特定できるデータベース上の行(レコード)は、それより多い属性の組み合わせでも特定できる性質を利用し、不要な探索を省略します。例えば、年齢と職業だけで特定できるレコードは、年齢と職業と本籍でも当然特定できるので、後者の組み合わせの探索は省略します。これにより、属性の膨大な組み合わせを計算する必要が無く効率的な探索が可能となりました。
- 個人データの特定しやすさを定量化する技術
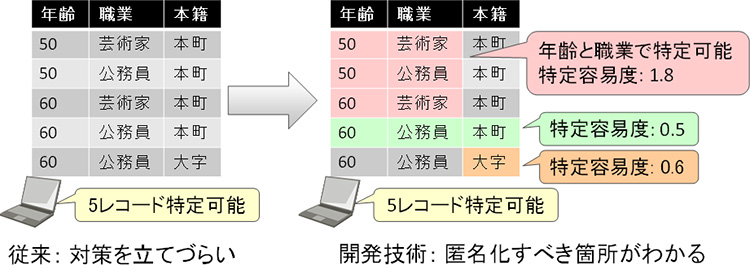
データ中で最も個人を特定しやすい属性の組み合わせを分析し、その容易度を定量化(注2)して個人の特定しやすさを比較できる技術を開発しました。これにより、優先的に匿名化すべき属性がすぐにわかるようになります(図3)。
また、本技術に加えて、データが漏えいした際の想定損害賠償額の算出や各種匿名化ガイドラインへの適合性を判定する技術も開発しました。これにより、幅広くプライバシーリスクが評価でき、そのリスクに基づき適切な匿名加工を容易に行うことができます。
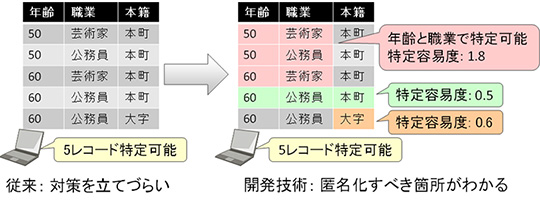
図3 開発技術の概要
拡大イメージ
{kind=link}
効果
本技術を用いることで、14属性、1万人のデータに対しても、3分以内という現実的な時間内での自動リスク評価が可能となりました。本技術は、データの分布に基づいたリスク評価を行うため、属性値の価値の重さを定義した辞書などは不要です。
本技術の利用により、医療分野を始め、金融・自治体などで、パーソナルデータをより早く安全に匿名加工して第三者提供することに貢献できます。これにより安全なデータ連携を可能にし、異業種の共創によるサービス・製品の品質向上につなげることが期待できます。
今後
富士通研究所は今後、実環境で効果を検証し、2017年度をめどに実用化していく予定です。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
本件に関するお問い合わせ
株式会社富士通研究所 知識情報処理研究所
セキュリティ研究センター
![]() 044-754-2681 (直通)
044-754-2681 (直通)
![]() prac-query@ml.labs.fujitsu.com
prac-query@ml.labs.fujitsu.com
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。