PRESS RELEASE (技術)
2012年8月20日
株式会社富士通研究所
業界初!ビッグデータ向けデータ処理の開発期間を約1/5に短縮する開発・実行環境を開発
大規模な蓄積データ処理と複合イベント処理を統合的に開発可能に
株式会社富士通研究所(注1)は、業界で初めて、ビッグデータと呼ばれる多種大量の時系列データ処理を統合的に開発・実行する環境を開発しました。
センサーデータや人の位置情報などの時系列データを代表とする、多種大量なデータが飛躍的に増え続けており、たとえば、Hadoopなどの並列バッチ処理(注2)技術や、データをリアルタイムに処理する複合イベント処理(注3)技術が開発されてきました。しかし、各処理技術の開発・実行環境は異なるため、データの分析結果から得た知見を素早く処理の記述に反映することは困難でした。また、弊社開発のイベント処理エンジン(注4)の性能を最大限引き出すには、サーバ間通信量の見積りなど並列アプリ設計の知識が必要でした。
今回、蓄積データ処理と、複合イベント処理のそれぞれの処理記述言語を統合的に扱える開発・実行環境を開発することで、分析処理からイベント処理までの開発期間を弊社事例で約1/5に短縮すること(POS分析に基づくクーポン発行で8週間から1.5週間)を可能にしました。また、本環境は今回開発した複合イベント処理の処理効率を自動的に向上させる並列性抽出機能も内蔵しており、複合イベント処理の処理記述から並列性を抽出して適切な機能の組合せを推奨する技術により、高効率な並列アプリ設計を手間なく実現できます。
本技術は、あらゆる場所で的確なサービスを提供するヒューマンセントリック・コンピューティングを支える技術の一つとして活用されます。
※本技術は、ソフトウェアエンジニアリングシンポジムSES2012(2012年8月27日~29日)で論文発表を予定しています。
開発の背景
近年、センサーデータや人の位置情報などの時系列データを代表とする、多種大量なデータが飛躍的に増え続けています。これらのビッグデータから、いかに価値ある情報を効率的に引き出し、各種のナビゲーションなどに素早く役立てられるかが強く求められています。
課題
ビッグデータを処理するために、蓄積された大量データを処理するHadoopなどの並列バッチ処理技術や、到着したイベントデータをリアルタイムに処理する複合イベント処理技術が利用されています。しかし、各処理技術に対応する開発・実行環境は統一されていませんでした。そのため、分析者が分析結果から得た知見を、素早く複合イベント処理に反映することが困難でした。
また、大量のイベントに対する複合イベント処理を行うには、クラウド上の複数の計算機を用いた高速処理が欠かせません。サーバを必要に応じて増減できるというクラウド特有の条件を考慮して弊社開発のイベント処理エンジンの性能を最大限引き出すには、処理をどのように分散させれば効率よく計算できるかをよく知った上で、短期間に多数到着するデータを並列に処理するアプリ設計が欠かせませんでした。
開発した技術
今回、ビッグデータの分析処理と複合イベント処理を統合した開発・実行環境を開発しました。この開発環境を用いて、たとえば、蓄積されたPOSデータから直近の購買動向を分析し、特定の顧客層に絞ってリアルタイムにクーポンを発行する処理をプログラミングなしで簡単に行うことができます。
この技術は(1)開発言語に依存せず簡単にプログラムの自動生成をする開発・実行環境の統合機能と、(2)複合イベント処理プログラムの処理効率を自動的に向上させる並列性抽出機能の二つからなっています(図1)。
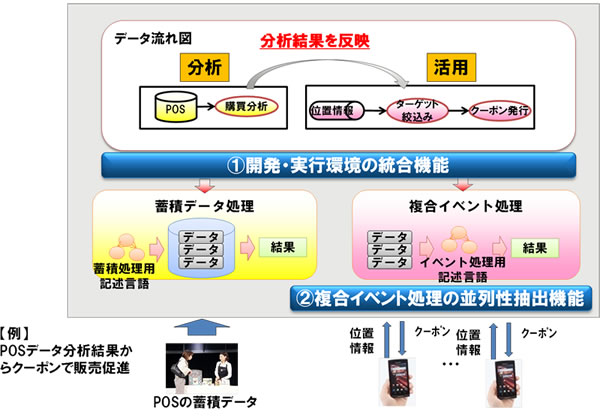
図1 開発・実行環境の全体像
これらの機能の特徴は、以下の通りです。
- 開発・実行環境の統合機能
データ流れ図とプロパティ(処理パラメーターに相当)で処理内容を定義すると、処理種別の判定結果に対応した自動生成パターンを用いて、バッチ処理またはリアルタイム処理向けのプログラムが自動生成されます。また処理内容に応じてデータ型変換などの処理が補完され、バッチ処理またはリアルタイム処理の実行環境へプログラムおよびデータが適切に配備・実行されます(図2)。
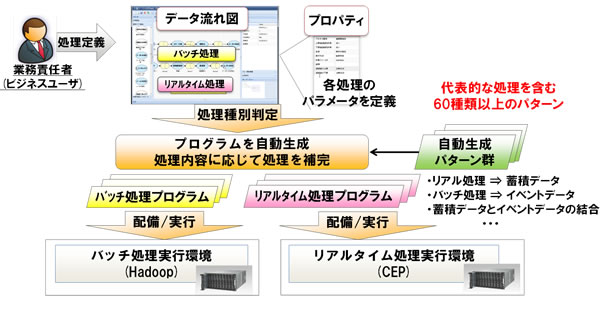
図2 開発・実行環境の統合機能 - 複合イベント処理の並列性抽出機能
開発・実行環境の統合機能が自動生成した、リアルタイム処理向けのプログラムから並列性を抽出し、一般的な通信量が減る基準に従ってどの並列性の組み合わせが良いかを自動的に推奨します(図3)。
リアルタイム処理には、到着するイベントをサーバに振り分けて並列に実行する処理があります。処理ごとに複数の振り分け方が可能で、どの振り分け方を選ぶかで性能が大きく異なります。一般的にはより細かな単位で振り分けた方が負荷を均等にしやすく良い性能が出ますが、イベント処理では通信を減らした方が良い性能が出ます。そこで、同じサーバで実行するように処理をできるだけまとめる振り分け方を選び、通信が少なく全体としての処理効率の良い組合せを推奨します。
リアルタイム処理の実行時は、イベントの量に応じてサーバ数を増減させつつ、推奨された並列性に従ってサーバに処理を割り当てることで高い性能を出すことができます。
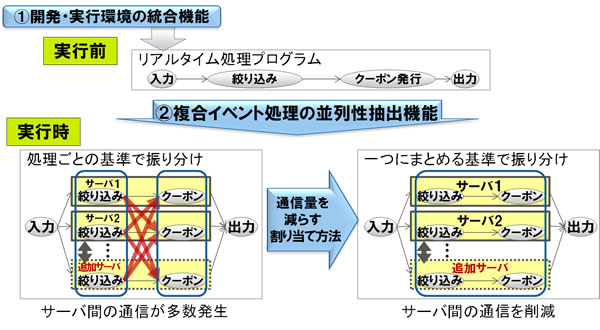
図3 複合イベント処理の並列性抽出機能
効果
- 開発・実行環境の統合機能
今回開発した統合的な開発環境を利用すると、弊社の事例では、分析プログラムの開発から複合イベント処理プログラムの開発までの期間を約1/5(8週間から1.5週間)に短縮することができました。また各処理のパラメーターをプログラミングなしで容易に変更できるため、分析結果から得た知見を素早くイベントの検出条件に反映するなど、開発環境における試行錯誤を容易に行うことができます。
- 複合イベント処理の並列性抽出機能
今回開発した複合イベント処理の並列性抽出機能を利用すると、サーバ数の動的な追加・削除の際にも再コンパイルなしに動的負荷分散可能な実行可能プログラムが生成されます。また、処理間でイベントの振り分け方が異なるサンプルプログラムで性能計測した結果、一つにまとめる基準で振り分けた場合は、処理ごとの基準で振り分けた場合に比べ通信量が60%減となるとともに、処理効率が3.5倍に向上することを確認しました(図4)。
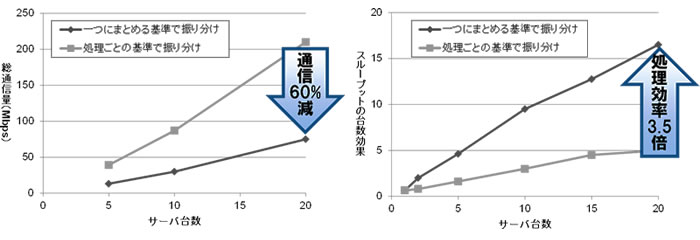
図4 複合イベント処理の並列性抽出機能の効果
今後
本技術は、今後より機能を充実させ、ビッグデータ向けプラットフォームやミドルウェアにおいて2013年度の製品化を目指します。大量のセンシングデータを収集、蓄積、分析して抽出した価値ある情報の活用を実現するために、富士通のサービスや製品への展開など、さまざまな用途への適用を検討して行きます。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
- 注1 株式会社富士通研究所:
- 代表取締役社長 富田達夫、本社 神奈川県川崎市
- 注2 Hadoopなどの並列バッチ処理:
- 蓄積しておいたデータに対し、分析などを一括して並列で実行する処理。Hadoopは、Apache Software Foundation(ASF)が開発・公開している、大規模データを効率的に分散・並列処理するオープンソースソフトウェア。
- 注3 複合イベント処理:
- Complex Event Processing(CEP)。ビッグデータから価値のある情報をリアルタイムに引き出すための手法。あらかじめ定義したルール(EPLで記述)にもとづいた処理をメモリ上で行うことでリアルタイム性を実現。なおEPLとは、Event Processing Languageのことで、複合イベント処理の内容を記述するための記述言語。
- 注4 イベント処理エンジン:
- PRESS RELEASE「ビッグデータの負荷増減にすばやく対応する分散並列型の複合イベント処理技術を開発」(2011年12月16日)
本件に関するお問い合わせ
株式会社富士通研究所
ソフトウェアシステム研究所 ソフトウェアイノベーション研究部
![]() 044-754-2675(直通)
044-754-2675(直通)
![]() soft-bigdata@ml.labs.fujitsu.com
soft-bigdata@ml.labs.fujitsu.com
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。