PRESS RELEASE
2012年7月30日
株式会社富士通研究所
業界初!人気データへのアクセス集中による分散ストレージの
性能低下を自動的に解消する技術を開発
アクセス集中を約70%緩和し、ICTサービスの安定運用を実現
株式会社富士通研究所(注1)は、分散ストレージにおいて人気データへのアクセス集中を自動的に解消してユーザーのアクセス時間の悪化を抑える技術を開発しました。
分散ストレージは、複数のサーバを組み合わせて1つのストレージ装置とします。サーバ台数を増加させることでストレージ容量や性能を増強できるため、日々増加していくようなデータの格納に適しています。また、同じデータの複製(レプリカ)を複数のサーバが同時に持つことでデータの信頼性とアクセス性能を高めています。しかし、格納された特定のデータへのアクセスが極端に増加すると、そのデータを持つサーバの負荷が増大し、ユーザーのアクセス時間が著しく長くなる場合がありました。
今回、突発的に人気が出たデータを即座に検出し、そのレプリカを増やすことでサーバへのアクセスを自動的に平準化させる技術を開発しました。従来は人手で対応していた性能低下の解消を自動で対処し、ユーザーのアクセス時間悪化を抑えることができます。開発した技術を分散オブジェクトストレージ(注2)に適用し、インターネット上でアクセス集中が発生したケースで評価したところ、アクセス集中を約70%緩和でき、アクセス時間に10倍以上の差が出ることを確認しました。
本技術により、あらかじめアクセスのパターンを予測することが困難なICTシステムの安定運用が可能になります。
本技術の詳細は、8月1日(水曜日)から鳥取市で開催される並列・分散・協調処理に関するサマー・ワークショップ(SWoPP鳥取2012)にて発表いたします。
開発の背景
近年、スマートフォンやセンサーの普及などにより飛躍的に増加したデータを蓄積、解析することで新たなビジネス価値が生み出されています。膨大なデータの蓄積には、ハードディスクやSSD(Solid State Drive)などのストレージデバイスを多く備えた複数のサーバを組み合わせて全体を一つのストレージ装置とする、分散ストレージが広く利用されています。ストレージの容量や性能の増強には、サーバを追加することで対応できます。また、データのレプリカを複数のサーバが同時に持つことでデータの信頼性を高めています(図 1)。
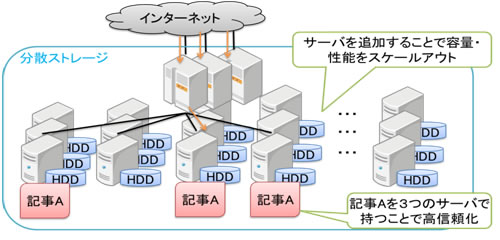
図1 分散ストレージ
課題
分散ストレージでは、人気データにアクセスが集中すると、台数に応じた性能が発揮できなくなる場合がありました。たとえば、社会的に関心の高い事件が起きた場合など、ある特定の情報にアクセスが集まり、その人気のデータを保持するサーバに負荷が集中して、サーバの台数に応じた性能が得られませんでした(図 2)。
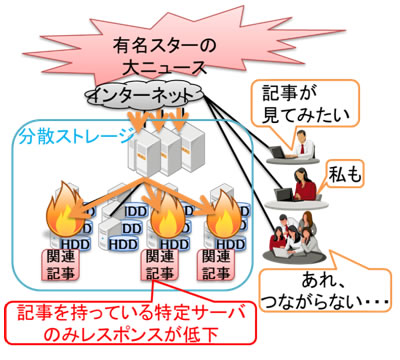
図2 人気データへのアクセス集中による性能低下
開発した技術
今回、人気データへのアクセス集中が起きたときにその検出を自動的に行い、そのレプリカを持つサーバ数を増加させることでアクセスを分散させる、「レプリカ数動的調整機構(Adaptive Replication Degree)」を開発しました。急激なアクセス集中を迅速に検出して解消し、アクセス時間の悪化を防ぐことができます。これにより、いつでも安定したアクセス性能を提供でき、あらかじめアクセスのパターンを予測することが困難なICTシステムの安定運用が可能になります。アクセス集中の検出とレプリカの増減は、レプリカ数動的調整機構が自動的に行うため運用の手間がかかりません。
レプリカ数動的調整機構を構成する特徴的な技術の詳細は、以下の通りです。
- 膨大なデータから急激なアクセス集中が起きた人気データを省メモリで迅速に検出する技術
急激なアクセス集中を検出するために、最近のアクセスに重みを付けた人気度(重み付き人気度)を少ないメモリ量で推定する人気度推定エンジンを開発しました(図3)。
今回開発した手法は、固定個数分だけデータのアクセス数を記録するので少ないメモリで実行できます。記録にないデータにアクセスがあった場合、最小アクセス数のデータと入れ替えます。この時、アクセス数を引き継ぐことで、高い精度で人気度を推定することができます。
また、一定アクセス回数ごとにアクセス数を縮減することで、最近のアクセスに重みをつけてカウントし、突発的な人気の変化も迅速に検出することができます。
- レプリカ数を適切に増減させる技術
増減させるレプリカ数を、アクセス集中している期間のアクセス頻度に合わせて変化させるアクセス集中度分析技術を開発しました(図4)。検出された人気データに対して、自動的に増やすべきレプリカ数を決定します。人気検出と予兆のそれぞれを判定する2つの閾値で、アクセス集中が起きている期間を検出します。その期間のアクセス頻度が大きいほど、より多くのレプリカを一度に増やしますので、アクセス集中の大きさに見合ったレプリカ数の増加が行われます。
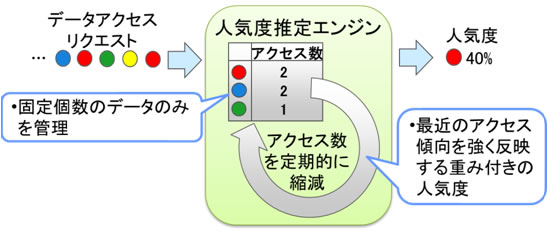
図3 人気度推定エンジン
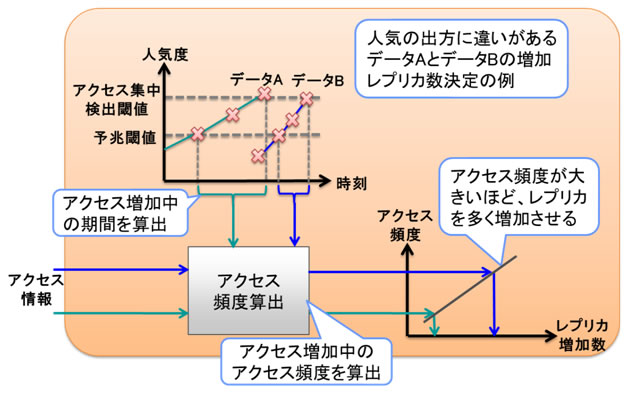
図4 アクセス集中度分析機構
効果
本技術の効果については、インターネット上で実際におきた、ある有名ポップスターの大ニュース発生時の大規模なアクセス集中を模したデータ(注3)を使い、64台のサーバで検証しました(図5)(図6)。サーバごとのアクセス頻度の変化を時刻ごとに調べると、従来の方式では関連したデータを持つサーバのみにアクセス集中が起き、そのアクセス頻度の増加率は約2.3倍でした。本技術を適用することで、アクセス頻度の増加率は0.7倍までに平準化され、アクセス集中を約70%削減できることを確認しました。
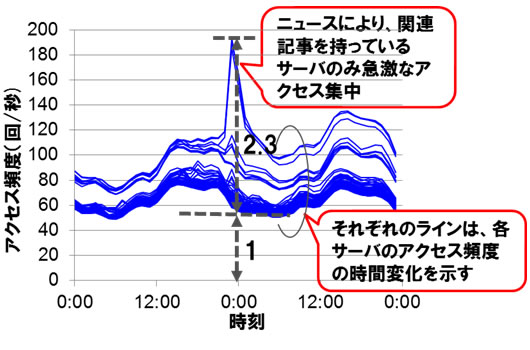
図5 従来方式におけるアクセス集中時の各サーバへのアクセス頻度の変化
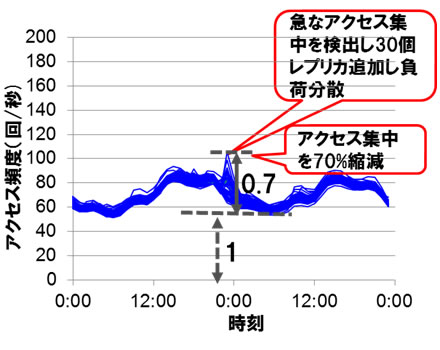
図6 本技術適用によるアクセス集中時の各サーバへのアクセス頻度の変化
また、ユーザーから見たアクセス時間に対する効果を検証するために、16台のサーバを用いた実験を行いました。図7は、従来の通常時の全データへの平均アクセス時間を1として、アクセス集中ありの時の全データへの平均アクセス時間およびアクセス集中している人気データへの平均アクセス時間について、従来と本技術を適用した場合とで比較したものです。全データへの平均アクセス時間で見ると、従来はアクセス集中時には通常時と比較して約4倍のアクセス時間がかかっていましたが、本技術を適用することで約1.2倍に抑えられることを確認しました。特に、アクセス集中を起こしているデータに関して、従来はアクセス時間が約15倍に悪化しているところを、本技術の適用により約1.4倍に抑えることができます。
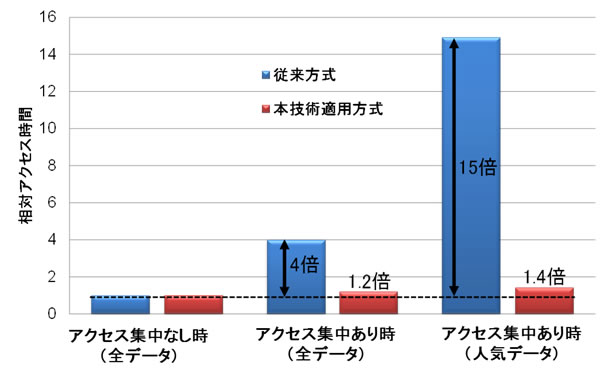
図7 負荷状態とデータ種別による各方式の相対アクセス時間
今後
本技術のさらなる性能向上および実証実験を進め、2013年度中の製品・サービスへの適用を目指します。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
- 注1 株式会社富士通研究所:
- 代表取締役社長 富田達夫、本社 神奈川県川崎市
- 注2 分散オブジェクトストレージ:
- データとその属性情報などを論理的な一つのまとまりとして分散管理するストレージ
- 注3 Wikimedia:
- Page view statistics for Wikimedia projects, Wikimedia (online), available form http://dumps.wikimedia.org/other/pagecounts-raw/ 2009年6月24日 23時 ~ 2009年6月26日 23時のデータ
本件に関するお問い合わせ
株式会社富士通研究所
ITシステム研究所 システムミドルウェア研究部
![]() 044-754-2632(直通)
044-754-2632(直通)
![]() nikaryo-press@ml.labs.fujitsu.com
nikaryo-press@ml.labs.fujitsu.com
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。