PRESS RELEASE (技術)
2017年3月17日
株式会社富士通研究所
IoTデータの分析を高速化するデータベース統合技術を開発
データ変換の最適化とデータ転送量削減で4.5倍高速化、さらに分散並列実行の自動化を実現
株式会社富士通研究所(注1)(以下、富士通研究所)は、企業の基幹システムとしてデータの分析に利用される関係データベースと、大量の非定型なIoTデータの蓄積に利用されるNoSQLデータベースを統合して高速に分析する技術を開発しました。
様々なIoTデバイスから出力される多様な構造を持つIoTデータの蓄積には、NoSQLと呼ばれる大量データの高速な蓄積に特化したデータベースが利用されますが、NoSQLデータベースを多機能な関係データベースに統合して横断的に分析する場合、データ構造を変換する処理時間を要するため、IoTデータなどの大量データの分析に時間がかかることが課題でした。
今回、関係データベースへの問い合わせを記述したSQLを解析することにより、データ変換最適化とデータ転送量削減技術、データを自動的に分割し分散並列実行基盤であるApache Spark(注2)で高効率に分散実行する技術を開発し、関係データベースにNoSQLデータベースを統合した高速な分析を可能としました。
開発技術をOSSの関係データベースであるPostgreSQL(注3)に実装し、NoSQLデータベースとしてOSSのMongoDB(注4)を使用して性能を測定したところ、データ変換最適化とデータ転送量削減技術により問い合わせ処理を4.5倍高速化できました。さらにApache Sparkで高効率に分散実行する技術によりノード台数に比例した高速化を実現しました。
本技術により、例えば、小売業の店舗などにおいて、顧客の動線や行動などを把握する様々なIoT機器を継続的に導入しながら、従来の基幹システムのデータと関連づけた新しい分析を素早く試みることが可能になるなど、顧客ごとに適した製品・サービスを提供するOne to Oneマーケティング施策の実現に貢献します。
本技術の詳細は、3月6日(月曜日)から3月8日(水曜日)まで岐阜県高山市で開催された「DEIM2017(第9回データ工学と情報マネジメントに関するフォーラム)」にて発表しました。
開発の背景
近年、IoTとセンサー技術が日々進化し、従来は入手困難だった情報が新たに取得できるようになってきました。これらの新しいデータと、既存の基幹・情報系システムのデータとを関連づけることにより、いままでできなかった多方面からの分析が可能となることが期待されています。
例えば小売業の店舗では、顧客が持つモバイル機器のWi-Fiなどの電波強度を分析することで顧客が店舗内でどこに滞在しているのかを把握したり、監視カメラの画像データを解析することで顧客の動線や年齢性別といった属性、商品を見たのか手に取ったのかといった詳細な行動を把握するなど、様々なIoTデータを取得することが可能となっています。これらのデータを、購買商品や売上データといった既存のビジネスデータとうまく組み合わせて活用することで、顧客ごとに適した製品・サービスを提供するOne to Oneのマーケティング施策の実現が期待されています。
課題
従来から、関係データベース上でNoSQLデータベースと組み合わせて分析する場合に、NoSQLデータベースに格納される非構造データを関係データベースで扱える構造データに変換するためのフォーマットを事前定義することで、高速にデータ変換して分析処理することができました。しかし、IoTデータの活用が強化されている中で、センサーを追加したり、同じセンサーやカメラからのデータでも、単に人数を抽出していたものがソフトウェアの更新により顧客の視線や行動、感情などの新しい分析情報が追加されるケースも増えており、事前にフォーマットを定義することは困難です。一方でデータ分析者が分析を素早く試みるためにはフォーマットの事前定義が不要な方法が望まれていますが、事前にフォーマットを決定することができない場合、データベースへの問い合わせ時の変換処理のオーバーヘッドが大きく、分析を行う際の処理時間が増大する課題がありました。
開発した技術
今回、事前にデータフォーマットを定義することなくNoSQLデータベースとの間でシームレスな分析を高速に行う技術と、分散並列基盤であるApache Sparkクラスタを活用した分析の高速化技術を開発しました。また、開発技術をPostgreSQLに実装し、NoSQLデータベースとしてJSON(注5)形式の非構造データを格納するMongoDB を使用し性能を測定しました。
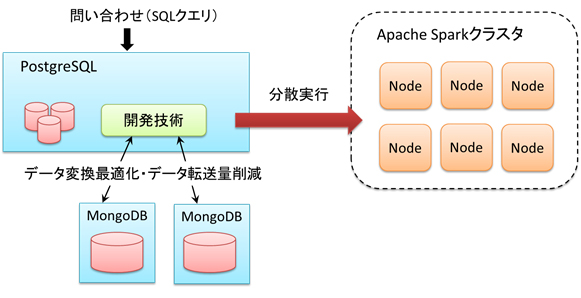
図1 開発技術の想定する構成
開発した技術の特長は以下のとおりです。
- データ変換最適化技術
NoSQLデータベースのデータへのアクセスが含まれたデータベース問い合わせ(SQLクエリ)を分析することで処理に必要となるフィールドとそのデータ型を指定する箇所を抽出し、データの変換に必要となるフォーマットを特定します。この結果をもとに問い合わせを最適化し、NoSQLデータを一括変換することでオーバーヘッドを削減し、従来のデータフォーマットを事前定義した処理と同等の性能を実現しました。
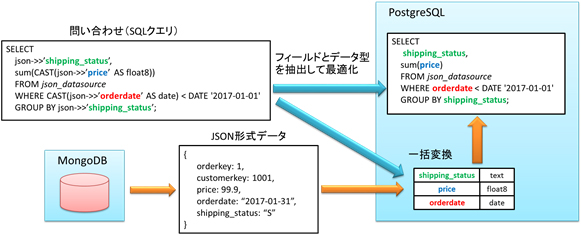
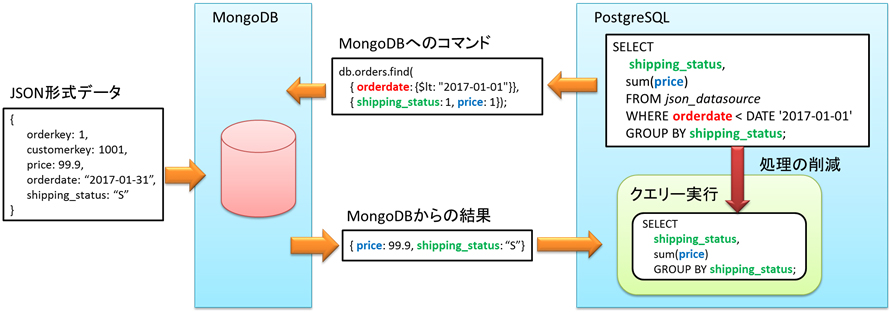
図2 JSON形式のデータ変換の最適化
拡大イメージ - NoSQLデータベースからのデータ転送量削減技術
データベース問い合わせを解析することにより、絞り込み条件の判定処理などの一部の処理をPostgreSQL側から NoSQL側へ移動する技術を開発しました。この技術により、NoSQLデータソースからデータ転送量を最小化し高速化します。
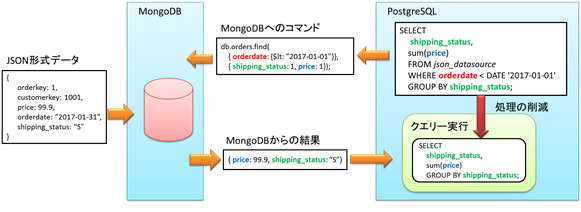
図3 NoSQL(MongoDB)からのデータ転送量の削減
拡大イメージ - 分散処理のための自動データ分割技術
複数の関係データベースとNoSQLデータベースを組み合わせた問い合わせをApache Spark上で効率よく分散実行する技術を開発しました。各データベースのストレージのデータ配置位置などの情報を元に、自動的にApache Sparkの各ノードの負荷が偏らない最適なデータの分割を決定します。
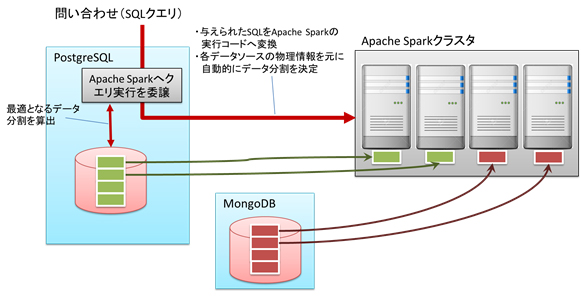
図4 Apache Sparkクラスタでの分散実行の自動化
{kind=link}
{kind=link}
効果
本開発技術をPostgreSQLに実装し、NoSQLデータベースとしてMongoDB を使用し性能を測定しました。意思決定支援システム(DSS:Decision Support System)の性能を測定するTPC-Hベンチマークの問い合わせを用いて測定したところ、前項1と2を組み合わせて適用した場合、従来技術に対して全体処理時間を4.5倍高速化しました。また前項3を用いて、4ノードのApache Sparkクラスタで実行することで、1ノードとくらべて3.6倍の性能向上を達成しました。
今回開発した技術を用いることで、センサーデータなどのIoTデータへのアクセスを、エンタープライズ分野で主流であるSQLインターフェースで効率良く行うことが可能になり、頻繁に更新されることが想定されるIoTデータのフォーマット変化に柔軟に対応しながら、IoTデータを含む分析を高速に処理することが可能となります。
今後
富士通研究所では開発技術を大規模なApache Sparkクラスタに適用した場合の検証をすすめ、2017年度中に富士通株式会社での製品化を計画中です。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
- 注1 株式会社富士通研究所:
- 本社 神奈川県川崎市、代表取締役社長 佐々木繁。
- 注2 Apache Spark:
- オープンソースの並列分散処理基盤。
- 注3 PostgreSQL:
- オープンソースの関係データベース。カリフォルニア大学バークレー校で開発されたデータベースシステム「POSTGRES」を元に、PostgreSQL Global Development Groupによって開発・維持されているフリーソフトウェアのデータベース。
- 注4 MongoDB:
- オープンソースのドキュメント指向のNoSQLデータベース。JSON形式のドキュメントを扱う。MongoDB, Inc.によって開発されている。
- 注5 JSON:
- JavaScript Object Notation。JavaScript プログラミング言語をベースとした軽量のデータ交換フォーマット。
本件に関するお問い合わせ
株式会社富士通研究所
コンピュータシステム研究所
![]() 044-754-2632(直通)
044-754-2632(直通)
![]() csi-db@ml.labs.fujitsu.com
csi-db@ml.labs.fujitsu.com
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。