PRESS RELEASE (技術)
2016年10月20日
株式会社富士通研究所
人やモノのつながりを表すグラフ構造のデータから
新たな知見を導く新技術「Deep Tensor」を開発
従来の Deep Learning の限界を超えて知を獲得する機械学習技術、IoT・金融・創薬分野で効果を検証
株式会社富士通研究所(注1)(以下、富士通研究所)は、人やモノのつながりを表現できるグラフ構造のデータに対して高精度な解析を可能とする機械学習技術「Deep Tensor(ディープ テンソル)」を開発しました。
今回、画像や音声では極めて高い認識精度を達成している既存のDeep Learning技術をグラフ構造のデータにまで適用可能な新技術を開発しました。グラフ構造のデータは、構造が複雑であり、大きさや表現方法など多様なデータが混在していますが、最先端の数学を活用してテンソル(注2)と呼ばれる統一的表現に変換することで、Deep Learning技術を用いてグラフ構造のデータを高精度に学習することが可能となります。
本技術を用いて、化合物のオープンなデータベースPubChem BioAssay(注3)のデータをもとに化合物の構造と活性の学習に適用したところ、従来技術の約100倍となる数10万種規模の化合物の構造と個々の活性の関係を学習することができ、既存技術では捉えきれなかった特徴が抽出されたことにより、既存技術に比べ約10%向上となる、約80%の活性予測精度を達成しました。
なお、本技術は富士通株式会社(以下、富士通)のAI技術「Human Centric AI Zinrai(ジンライ)(以下、Zinrai)」に活用していきます。
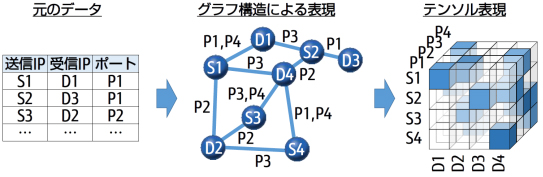
図1 グラフ構造で表現できるデータとテンソル表現
開発の背景
近年、機器間通信を行うIoTや口座間取引のログデータを扱う金融、化学物質の組成のデータベースを活用する創薬など様々な分野で、人やモノのつながりを表すグラフ構造として表現できるデータ(図1)が大量に蓄積され続けています。これまで富士通研究所では、LOD(注4)と呼ばれるグラフ構造データの検索・分析の技術を開発してきました。これらのグラフ構造のデータを高精度に分類し、解析していくことで、新たな価値の創造やビジネス領域の開拓につながることが期待されています。
課題
従来、グラフ構造のデータの分類では、あらかじめ人が注目した一部分のグラフが、分類対象のグラフ構造データ中に含まれるかどうかに基づいて分類していました。しかし、大量のグラフ構造データを分類の対象とする場合、あらかじめ注目した部分グラフでは表現できていない特徴が多く存在しているため、高精度な分類を実現することに限界がありました。
Deep Learning技術は、データの特徴要素を自動的に抽出することができ、画像や音声の認識などで注目されていますが、グラフ構造のデータは、構造が複雑であり、大きさや表現方法など多様なデータが混在しているため、Deep Learning技術を適用することが困難でした。
開発した技術
今回、人やモノのつながりを表す様々なグラフ構造のデータを高精度に学習できるDeep Learningの新技術を開発しました。開発した技術は以下のとおりです。
- グラフ構造のデータを統一的表現に変換する、新たなテンソル分解技術
多様な表現形式を持つグラフ構造のデータを、ベクトルや行列を拡張したテンソルと呼ばれる数学表現を用いて表現します(図1)。これを最先端のデータマイニング技術であるテンソル分解(注5)と呼ばれる数学的操作を用いて統一的な表現形式に変換します(図2)。従来は、類似するグラフ構造のデータを、必ずしも類似するテンソル表現に変換することができませんが、今回、基準となる任意のパターンとの類似度を最大にするようにテンソル分解を行う技術を開発しました。
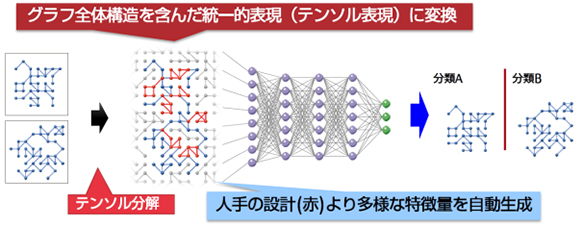
図2 本技術によるグラフ構造データの分類 - ニューラルネットワークの学習と同時に統一的表現を最適化する技術
ニューラルネットワークの学習過程で通常用いられている誤差逆伝搬法(注6)の適用範囲をテンソル表現まで拡張することにより、分類精度を最大化するように統一的表現も同時に最適化します(図3)。具体的には、基準となるパターンを変化させたときのニューラルネットワークの分類誤差の変動の大きさからテンソル表現の基準パターンを更新します。
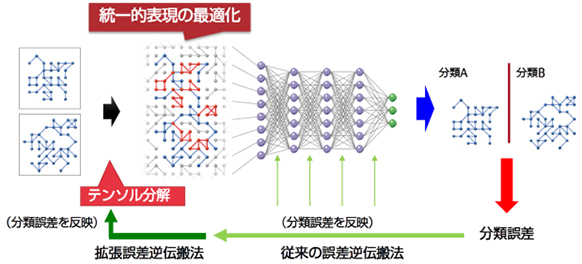
図3 ニューラルネットワークの学習と統一的表現の最適化
効果
今回の新しいDeep Learning技術により、コンピュータやIoT機器などの通信ログや、金融取引、化学組成など、グラフ構造で表現できるデータを活用して新たな分析ができるようになります。
本技術を化合物の構造と活性のオープンなデータベースPubChem BioAssayのデータに適用し、コンピュータ上で医薬品の候補化合物を探索するバーチャルスクリーニングに適用した実験では、サポートベクターマシン(注7)を用いた従来技術の約100倍となる数10万種規模の化合物の構造と活性の関係を学習することができました。既存技術では捉えられていなかった特徴が抽出されたことにより、既存技術に比べ約10%向上となる、約80%の活性予測精度を達成しました。これにより、医薬品開発において課題となっている開発期間やコストを大幅に削減することが期待されます。
また、本技術を侵入検知のベンチマークデータ(注8)に適用し、ホスト間の通信関係を表すグラフ構造のデータから不正や攻撃の検知を行う実験では、サポートベクターマシンを用いた既存手法に比べ、2割以上の誤検知の削減に成功しました。これにより、ネットワーク監視業務の効率化が期待できます。そのほか、本技術を電子通貨の取引履歴や融資仲介サービスの融資履歴などに適用することにより、不正な金融操作の高精度な検知や融資可否の精緻な判定などが可能となります。
今後
富士通研究所は、グラフ構造データの分類技術のさらなる高精度化を進め、「Zinrai」のコア技術として本技術の2017年度上期中の実用化を目指します。また、より多様なデータ形式へのDeep Learning技術の適用拡大を進め、様々な分野において高度なデータ分析を実現していきます。
エンドースメント
大規模データの学習に強いDeep Learningは、生命科学分野の多種多様かつ大量データの学習を可能とする技術として、製薬業界でも注目を集めています。なかでも、医薬品の薬効や副作用などの様々な作用の予測に適した化合物の特徴量を設計することが大きな課題となっています。予測に適した特徴量を学習データから自動的に生成することのできる富士通の新たなDeep Learningは、創薬分野に大きなインパクトを与える技術として期待します。
京都大学 大学院医学研究科 人間健康科学系専攻 ビッグデータ医科学分野 教授 奥野 恭史
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
- 注1 株式会社富士通研究所:
- 本社 神奈川県川崎市、代表取締役社長 佐々木繁。
- 注2 テンソル:
- 行列やベクトルなどの概念を一般化した、多次元の配列で表現したデータ。
- 注3 PubChem BioAssay:
- 薬理および毒性試験における、化合物の構造と活性データを収録した、世界最大のデータセット。
- 注4 Linked Open Data(LOD):
- 世界中で公開されている互いにリンクが張られたデータ。
- 注5 テンソル分解:
- 多次元の配列を、要素間の多重の相関関係の和に分解する技術。
- 注6 誤差逆伝搬法:
- ニューラルネットワークの分類誤差を減少させるアルゴリズム。
- 注7 サポートベクターマシン:
- データを精度よく分離できる、高次元空間の平面を算出する機械学習技術。
- 注8 ベンチマークデータ:
- DARPA Intrusion Detection Data Sets。
関連リンク
- オープンデータの活用革新! リンクが張られた公開データ(LOD: Linked Open Data)向け大規模データ格納・検索技術を開発(2013年4月3日 プレスリリース)
- 当社が培ったAI技術を「Human Centric AI Zinrai」として体系化(2015年11月2日 プレスリリース)
本件に関するお問い合わせ
株式会社富士通研究所
知識情報処理研究所
![]() 044-754-2328(直通)
044-754-2328(直通)
![]() deeptensor@ml.labs.fujitsu.com
deeptensor@ml.labs.fujitsu.com
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。