PRESS RELEASE (技術)
2016年3月15日
株式会社富士通研究所
ゲノム情報の解析処理を高速化する技術を開発
データベース上で大規模解析処理を約400倍高速化し、ゲノム医療研究の推進に貢献
株式会社富士通研究所(注1)(以下、富士通研究所)は、ゲノム上の変異情報と、疾患や生活習慣などによる環境情報との関連性をデータベース上で解析する際に、従来手法に比べて約400倍高速に処理する技術を開発しました。
ゲノム医療の進展により、ゲノム・遺伝情報と臨床・環境情報を組み合わせて解析することで、遺伝要因と環境要因の関連性を探索する研究が行われています。このような研究では多様な角度から解析するためにゲノム情報をデータベースに格納して処理しますが、膨大な規模のゲノムデータを扱うため、処理に時間がかかるという課題がありました。
今回、富士通研究所は、大規模なゲノム情報をデータベース内で高速に解析処理可能な新しいデータ構造を導入することで、処理の高速化を実現しました。
本技術により、従来は短時間で得ることが難しかった知見を得ることが可能になり、ゲノム医療研究の推進に貢献できます。
本技術の詳細は、2016年3月15日(火曜日)からフランス・ボルドーで開催予定の国際会議「EDBT 2016 (19th International Conference on Extending Database Technology)」にて発表します。
開発の背景
現在、膨大なゲノム情報を高速に読み取る専用装置である次世代シーケンサの登場により、ゲノム情報を測定・解析して、疾患へのかかりやすさや、予測される薬の効果や副作用を把握し、個人向けの予防・治療計画を立てるといったゲノム医療の普及が始まっています(図1下)。ゲノム医療をより効果的に実施するには、ゲノム情報と、臨床・環境情報との関連性を調べて知見を得ておくことが必要です。一人当たり約30億文字におよぶ全ゲノム情報の中で、個人差の要因となるバリアント(注2)と呼ばれる変異箇所は数千万にのぼります。例えば2型糖尿病では、発症に関連する要因として、数十箇所ほどのバリアントと、いくつかの生活習慣が知られており、それぞれが相乗的な関係性を持つこともあります。このような知見を得るための手法として、大規模にゲノム情報と臨床・環境情報を集めて統計的な解析を行う、ゲノムワイド関連解析(注3)があります。(図1上)。
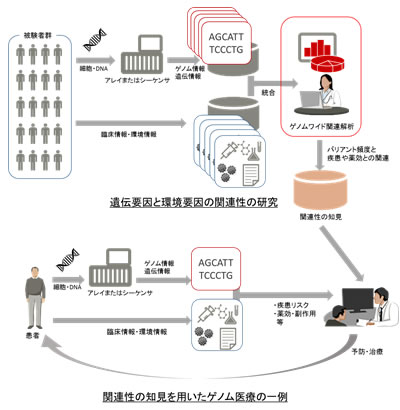
図1 ゲノムワイド関連解析とゲノム医療の一例
拡大イメージ
{kind=link}
課題
10万人の母集団データに対して1つのバリアントについて集計すると、既存のオープンソースデータベースソフトを用いた場合に約1秒の処理時間がかかります(富士通研究所調べ)。このため、例えば一つの疾患について、1,000万箇所のバリアントの集計を10万人規模の母集団で行うとすると約120日かかる計算になります。ゲノムワイド関連解析においては、このような解析を繰り返し行う必要があるため、処理の高速化が課題となっています。
開発した技術
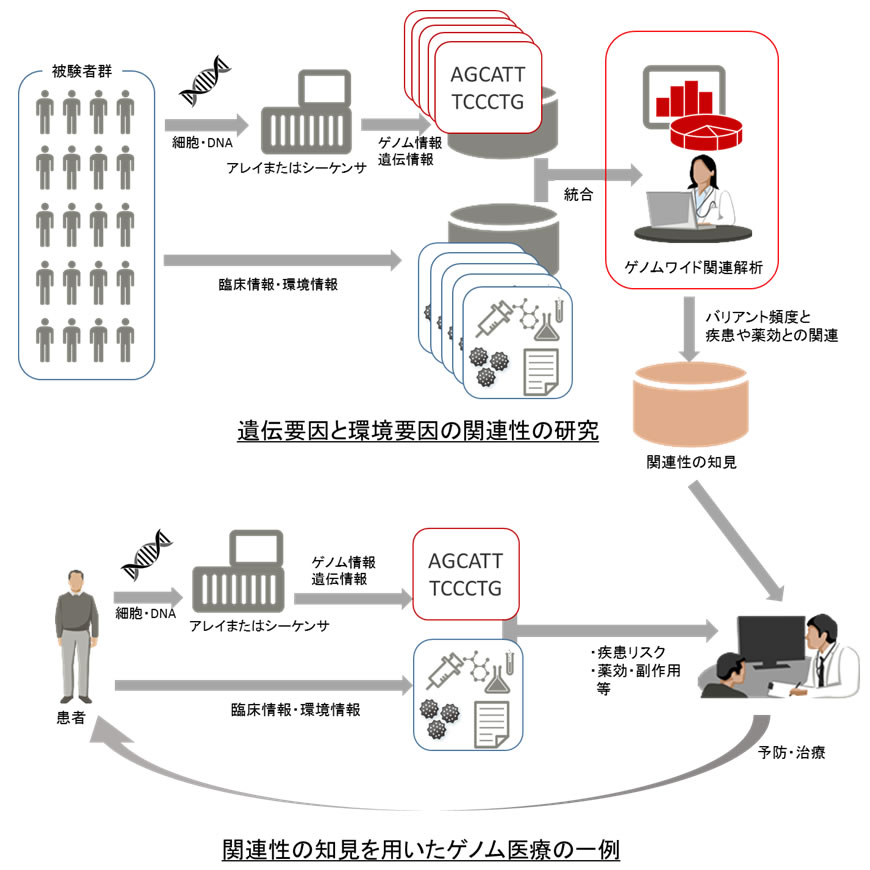
今回、ゲノムワイド関連解析処理を高速化するために、データベース上でゲノム情報の高速な集計処理を可能にするデータ構造(以下、ゲノム型)とその処理方法を開発しました。 ゲノム型は一人のゲノム情報をデータベース上の1列(カラム)で格納するデータ構造で、各バリアントの情報を固定ビット長にコード化して格納します(図2)。
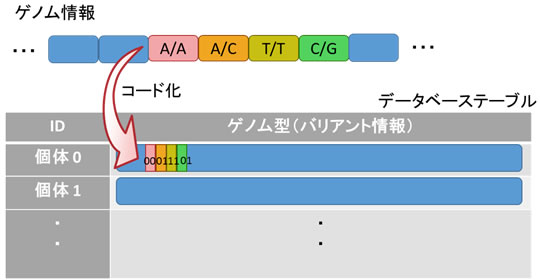
図2 ゲノム型カラム
ゲノム型の特長は以下のとおりです。
- バリアントを同時に集計可能なデータ構造
従来のデータベースのテーブル構造に各バリアント情報を格納する場合、バリアント数に相当する数のデータベースへの問い合わせを繰り返す必要がありました(図3)。今回開発したゲノム型ではバリアントを一列に格納することにより、1つの問い合わせで同時に集計することを可能とし、1バリアントあたりの集計処理性能を大幅に向上させました(図4)。
- 高速な集計処理を実現するコード化技術
バリアントの種類は大半が計算機上で2ビット長のコードに置換することができます。しかし、3ビット以上の複雑なコードに置換されるバリアントも多数あるため、複数のビット長が存在する可変長データも扱う必要がありますが、可変長データ構造を扱うことで集計処理に時間がかかってしまいます。今回、このような可変長データを、固定ビット長構造を崩さずに格納して集計処理する方式を考案し、高速な集計処理を実現しています。
また、コード化によって、文字列でバリアントを格納する場合に比べて、ゲノム情報サイズが16分の1に削減されます。これにより、数十万人規模の大規模データについてもインメモリで高速に処理することが可能です。
効果
今回開発した技術により、数千万箇所にのぼる全ゲノムバリアントを用いたゲノムワイド関連解析が、一般的な計算機上にて短時間で実行可能になります。また、これまで解析時間の制約から調査するバリアントを限定していたことで見逃されていた疾患との関連性についてもカバーできるようになります。これにより、次世代のゲノム医療研究や、ゲノムをはじめとする生物内にある分子情報を網羅的に解析するオミックス・ビッグデータ解析の推進に貢献します。
今後
さらなる集計処理の高速化および運用上必要となる機能の実装を進め、医療機関との共同研究、倫理審査を経て、ヘルスケアシステム事業本部のソリューションに適用する予定です。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
- 注1 株式会社富士通研究所:
- 本社 神奈川県川崎市、代表取締役社長 佐相秀幸。
- 注2 バリアント:
- ヒトのゲノム配列は、DNAを構成する4種類の塩基(アルファベットでA、G、C、Tで表現する)が約30億個並んだ構造になっており、ゲノム配列上において個人間でところどころに存在する変異や多型といわれる違いが個人差の由来となる。この違いをバリアントと呼ぶ。ヒトのゲノム配列の中に占めるバリアントの割合は1%以下だが、配列全体で約30億塩基対があるため、数にすると数千万箇所存在する。
- 注3 ゲノムワイド関連解析:
- 数十万以上のバリアント(遺伝型)と、疾患や薬効など(表現型)の関連性を統計的に調べる網羅的な解析方法。GWAS(Genome-Wide Association Study)とも呼ばれる。
本件に関するお問い合わせ
株式会社富士通研究所
コンピュータシステム研究所
![]() 044-754-2632(直通)
044-754-2632(直通)
![]() genome-db@ml.labs.fujitsu.com
genome-db@ml.labs.fujitsu.com
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。