PRESS RELEASE (技術)
2015年2月26日
株式会社富士通研究所
タイムリーな大規模データ分析を実現する列形式のデータベース処理エンジンを開発
サーバ1台でオープンソース・データベースのPostgreSQLの分析処理を50倍以上高速化
株式会社富士通研究所(注1)は、データベースシステム上のタイムリーな大規模データ分析を可能にする、列形式のデータ格納と処理エンジンを開発しました。
近年、大量のデータを読み出して分析するため、更新処理に適した行形式と呼ばれるデータ格納方式に加え、分析に適した列形式と呼ばれる格納方式を用いた高速化手法がとられています。しかし、行形式データの更新を列形式のデータに自動的に反映できない、あるいは列形式データのサイズがメモリ搭載量の制約を受けるといった課題がありました。
今回、オープンソース・データベースであるPostgreSQL上で、メモリ搭載量によらず、行形式データの更新を瞬時に列形式に反映できるデータ格納と、列形式データを高速に処理する実行エンジンを開発しました。一般のデータベースシステムが備えたインデックス(注2)という仕組みの中で高速に分析でき、行形式や列形式といった格納方式の違いを開発者が意識することなく利用できます。列形式データ処理に適した並列分析処理エンジンにより、従来と比較して1CPUコアで4倍、15CPUコア搭載のサーバ1台で50倍以上の高速な分析が可能になります。
本技術により、メモリ容量が少ない中小規模のコンピュータシステムでも、最新のデータが反映されたリアルタイムなデータ分析が可能になります。
本技術の詳細は、3月2日(月曜日)から福島県郡山市で開催される「DEIM2015 (第7回データ工学と情報マネジメントに関するフォーラム)」にて発表いたします。
開発の背景
データベースシステムは、処理結果を即座に端末に返すオンライントランザクション処理(Online Transaction Processing、OLTP)を効率的に行うことができるため、業務システムのデータ蓄積や活用などデータ更新処理の中心的な存在として幅広い分野で利用されています。
課題
近年、ビジネスの現場では大量のデータをタイムリーかつ高速に分析したいという要望をうけ、一つのデータベースシステム上でOLTPと大量のデータ分析処理を同時に処理する必要性が高まっています。OLTPに適した行形式に対して、データ分析処理では列形式のデータが適していますが、データ更新処理が遅くなるという欠点があります。これを解決するため、近年では行形式に加え、列形式のデータも格納して分析処理を高速化する方式がとられています。しかし、従来技術では行形式データを更新しても自動で列形式に反映できなかったり、メモリ搭載量の制約を受けるといった課題がありました。
開発した技術
今回、オープンソース・データベースであるPostgreSQL上で、行形式データの更新を瞬時に反映でき、メモリ搭載量によらない列形式のデータ格納と、列形式データを高速に処理する実行エンジンを開発しました。列形式のデータの管理方法を工夫することにより大容量の列形式データ格納を実現しています。一般のデータベースシステムが備えたインデックスという仕組みの中で高速に分析でき、行形式や列形式といった格納方式の違いを意識することなく利用できます。列形式データ処理に適した並列分析処理エンジンにより、読み出し、フィルタリング、集計を実行するDBT-3ベンチマーク(注3)において従来と比較して1CPUコアで4倍、15CPUコア搭載のサーバ1台で50倍以上の高速な分析が可能になります。
開発した技術の特長は以下のとおりです。
- 大容量の列形式データの格納
メモリに入りきらない大容量の列形式データを効率的に管理するため、「エクステント」と呼ぶ大きな単位(約26万レコード単位)で、領域の確保や削除、さらに空き領域回収といったデータ領域管理を行い ます。大きな単位で管理すると同時に分析処理が長時間待たされるという問題が発生しますが、これを防ぐために、エクステントに同時実行制御(MVCC)(注4)を導入し、分析処理とデータ領域管理が同時に走行できるようにしました。
- 列形式インデックス(カラムストアインデックス)
他のインデックス同様、列形式インデックス(カラムストアインデックス)を作成することで、データベースが問い合わせする内容に応じて、適切なデータ格納方式(行形式あるいは列形式)を選び処理を行うようになります。またカラムストアインデックスを作成した元の行形式データの更新にも追随して、列形式データも自動的に更新されます。このため利用者は格納方式の違いを全く意識することなく利用することができます。
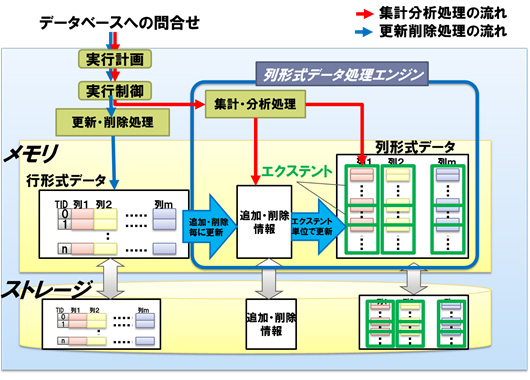
図 開発技術のアーキテクチャー
拡大イメージ - 列形式データ処理に適した分析処理エンジンと独自共有メモリ機構を用いた並列処理
列形式データにすることでデータの読み出し性能を上げるだけでは、列形式データの効果を十分に引き出すことができません。そこで複数データに対して一括して同じ処理を行う方式(ベクトル処理方式)を分析処理エンジンに採用することで1並列時の性能を向上させました。また並列実行による分析処理の高速化の効果を高めるために、PostgreSQLで並列動作する複数のプロセス間が低遅延でデータの受け渡しができるようメモリ共有の仕組みを新たに開発しました。これにより15コアサーバ1台で、従来のPostgreSQLの50倍以上の性能を達成することが可能になりました。
{kind=link}
効果
今回開発した技術を用いることで、メモリ搭載量が小さい既存の中小規模システム上において、従来では不可能であったリアルタイムの分析が実現でき、ビッグデータの活用が可能になります。
今後
富士通研究所は、富士通のデータベース製品「FUJITSU Software Symfoware Server」への搭載に向け、本技術の2015年度中の実用化を目指します。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
- 注1 株式会社富士通研究所:
- 本社 神奈川県川崎市、代表取締役社長 佐相秀幸。
- 注2 インデックス:
- データベースの検索を速くするためのヒント情報。
- 注3 DBT-3ベンチマーク:
- 意思決定支援システム(DSS)の性能を測定するベンチマーク。
- 注4 MVCC:
- MultiVersion Concurrency Control(同時実行制御)。複数の利用者からの同時処理要求を、一貫性を保って処理するための仕組み。多くのデータベースシステムで利用。
本件に関するお問い合わせ
株式会社富士通研究所
ICTシステム研究所 データプラットフォーム研究部
![]() 044-754-2632(直通)
044-754-2632(直通)
![]() csi-db@ml.labs.fujitsu.com
csi-db@ml.labs.fujitsu.com
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。