PRESS RELEASE (技術)
2014年6月13日
株式会社富士通研究所
世界最高速!CPU間通信向け56Gbps受信回路を開発
データ通信速度を2倍高速化し、次世代サーバやスパコンの高性能化に貢献
株式会社富士通研究所(注1)は、次世代サーバに搭載されるCPUなどのチップ間データ通信において、世界最高速である毎秒56ギガビット(Gbps)の高速データを受信可能な受信回路を開発しました。
近年、サーバのデータ処理能力を向上させるため、CPUの高性能化とともに、CPUなどのチップ間のデータ通信速度の高速化が求められていますが、受信時に劣化した信号波形を補正する回路の処理能力向上が課題でした。
今回、受信信号の品質劣化を補償する回路に対して、新たなアーキテクチャーである先読み回路を適用し、並列処理を実現して回路の動作周波数を高め、従来の2倍の高速動作を実現しました。
本技術により、次世代サーバやスーパーコンピュータなどの高性能化が期待されます。
本技術の詳細は、6月9日(月曜日)から米国ハワイで開催される「2014 Symposia on VLSI Technology and Circuits」にて発表します(VLSI Circuits 発表番号11-2)。
開発の背景
近年、クラウドコンピューティングを支えるデータセンターなどに向け、サーバのデータ処理能力の向上が一層求められています。このため、CPU性能の向上に加え、CPUを多数接続した大規模システムも構築されており、CPUが搭載された筐体内や筐体間でやり取りするデータ量はますます増加しています。これに対応するため、現在のサーバでは、データ通信速度が毎秒数ギガビットから十数ギガビットへと高速化されています。しかし、データ処理量が急激に増加すると予想されており、次世代の高性能サーバに向け、現行の2倍の高速化に当たる56Gbpsの通信速度への期待が高まっています。また、筐体間の光伝送などで用いられる光モジュールの通信速度についても、OIF(注2)にて56Gbpsの標準化が進んでいます。
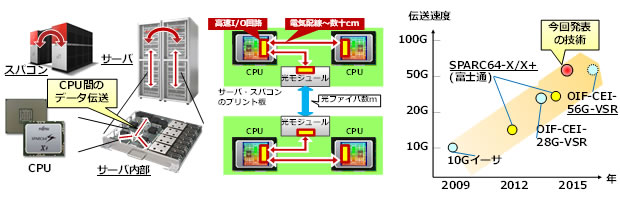
図1 サーバ内部のCPU間や筐体間などをつなぐ高速データ通信
課題
受信回路の高速化には、劣化した入力信号波形を補償する回路であるDFE(注3)の処理能力向上が有効です(図2)。
DFEの基本的な考え方は、1ビット前のビット値に応じた入力信号を補正し入力信号の変化を強調するというものですが、実際の回路設計ではあらかじめ補正した候補を2つ用意しておきビット値に応じて選択するという動作になります。補正は、例えば、1ビット前が0の場合、入力信号にプラス方向の補正(加算)することで0から1への変化を強調し、1ビット前が1の場合、入力信号をマイナス方向に補正(減算)することで1から0への変化を強調します。0が続く場合には、プラス方向の補正により信号のレベルは上がりますが、1/0判定回路の判定レベルを超えないため問題になりません。
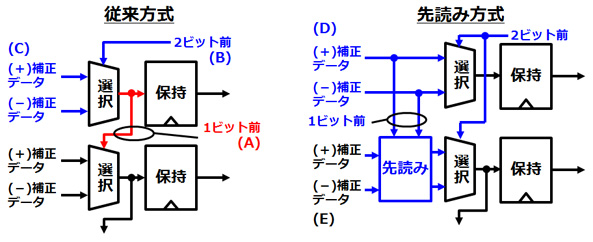
56Gbpsの通常の回路設計でDFEは16個を連結させて使用しますが、例えば4個の場合は、4分の1の周波数で動作させます。したがって、28Gbpsで4個の場合、4分の1の周期は142ピコ秒となり、この時間内に4ビット分の補正をすべて完了することができました。しかしながら、56Gbpsの場合、4分の1の周期は71ピコ秒となり、半分の2ビット分の補正までしか収めることができず、タイミングエラーとなっていました(図3)。
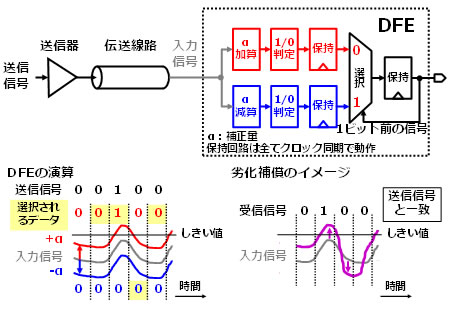
図2 高速化の主要技術である信号劣化補償回路(DFE)とその役割
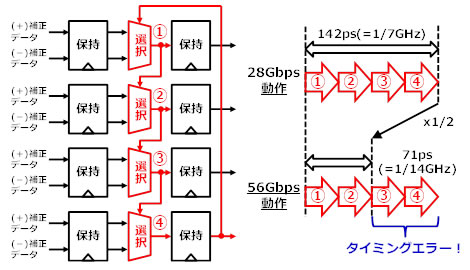
図3 従来のDFEの実際の構成と56Gbp動作時の課題
拡大イメージ
{kind=link}
開発した技術
今回、1ビット前の選択結果から得られる候補2つをあらかじめ計算しておき、2ビット前のビット値が決定すると1ビット前のビット値と現在のビット値が同時に決定することで並列処理が可能な先読み方式を新たに考案し、これにより演算時間が短縮されるため、56Gbpsで動作する受信回路の開発に成功しました(図4)。
開発した技術の特長は以下のとおりです。
- 先読み方式による補正処理
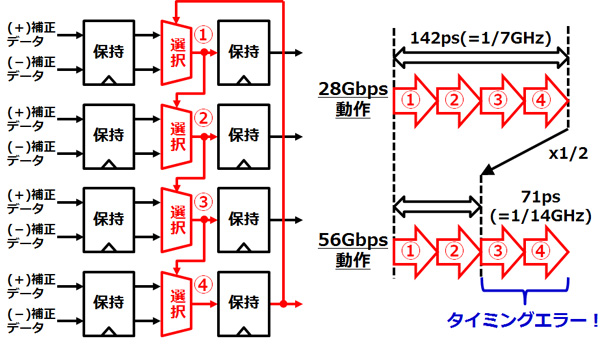
従来方式では、1ビット前の選択回路の結果(A)は、2ビット前の選択回路の結果(B)と1ビット前の選択回路の入力信号(+/-補正データ)(C)の組合せ回路で実現されています。先読み方式では、1ビット前の選択回路の入力信号(+/-補正データ)(D)と現在の選択回路の入力信号(+/-補正データ)(E)を先に先読み回路で組み合わせて選択回路の候補をあらかじめ算出しておきます。こうすることで、1ビット前の選択回路の結果を使わずに、2ビット前の選択回路の結果のみで従来方式と同じ機能が実現できます。
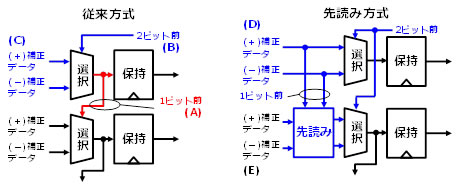
図4 先読み方式の原理
拡大イメージ - 保持回路による先読み処理の並列化
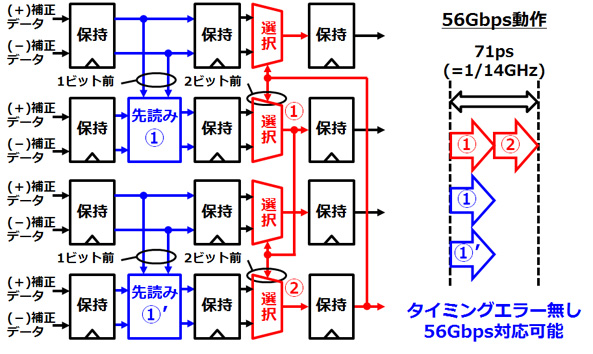
DFEの1ビットおきに適用した複数の先読み回路は、独立に動作可能です(図5)。今回、選択回路と先読み回路の間に保持回路を挿入し、各保持回路の入出力を同期させることで、並列処理を可能にしました。
先読み回路の演算時間は、選択器の選択時間とほぼ同じであるため、全体の演算時間は2ビット前のデータから決定する選択器の数に依存し、4ビット構成の場合2となります。これにより、56Gbpsの4分の1周期である71ピコ秒に演算を収めることができます。その結果、従来の2倍の通信速度である56Gbpsでのデータ受信が可能となりました。
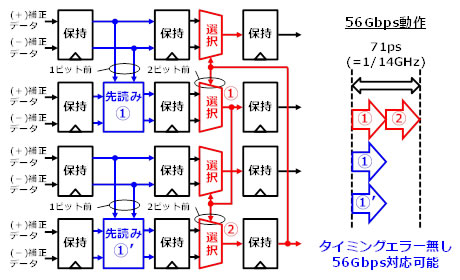
図5 新規構成のDFEとその効果
拡大イメージ
{kind=link}
{kind=link}
効果
本技術により、次世代サーバやスーパーコンピュータ内において、CPUの性能が倍になっても、ピン数を増やす事なくCPU間通信を広帯域化することができ、CPUを多数接続した大規模システムでの性能向上に大きく貢献することが期待されます。また、光モジュール通信の規格であるOIF標準規格にも対応でき、OIF-CEI-28Gの光モジュール通信で400Gbpsイーサネットを構築する場合に比べて並列動作する回路数(レーン数)を半分にすることができるため、光モジュールの小型化による低電力化やシステム全体の高性能化も期待されます。
今後
富士通研究所は、開発した技術をCPUや光モジュールのインターフェース部などに適用し、2016年度の実用化を目指します。さらに、次世代サーバやスーパーコンピュータなどの製品への適用も検討して行きます。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
- 注1 株式会社富士通研究所:
- 代表取締役社長 佐相秀幸、本社 神奈川県川崎市。
- 注2 OIF:
- Optical Internetworking Forumの略。
- 注3 DFE:
- Decision Feedback Equalizerの略。
本件に関するお問い合わせ
株式会社富士通研究所
ICTシステム研究所 サーバテクノロジ研究部
![]() 044-754-2692(直通)
044-754-2692(直通)
![]() hsio2014@ml.labs.fujitsu.com
hsio2014@ml.labs.fujitsu.com
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。