PRESS RELEASE
2012年12月5日
富士通株式会社
世界初! Hadoopとの連携を実現したCOBOL「NetCOBOL V10.5」を販売開始
並列分散処理により、バッチ処理時間を従来の約18分の1に短縮
当社は、COBOLバッチアプリケーションをApache Hadoop(注1)で並列分散処理し、バッチ処理時間を大幅に短縮する機能を追加したCOBOL開発・運用ソフトウェア「NetCOBOL V10.5」を、本日より販売します。
本製品は、Hadoopとの連携を実現した世界初(注2)のCOBOL開発・運用ソフトウェアです。「NetCOBOL」で開発したバッチアプリケーションや他社のCOBOLで開発されたバッチアプリケーションを、再コンパイルによりHadoopで並列分散処理できるため、お客様は既存のCOBOLデータやアプリケーションに手を加えることなく、バッチ処理時間を大幅に短縮することができます。
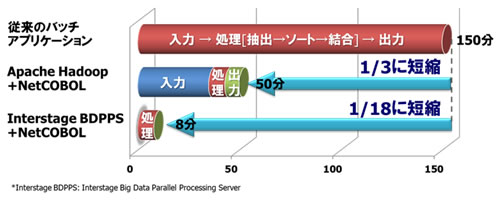
例えば、128GBのデータを16多重で集計した場合、従来のバッチ処理に比べ、Apache Hadoopベースの当社製品「Interstage Big Data Parallel Processing Server」との組み合せで、バッチ処理時間を約18分の1に短縮しました。本製品とApache Hadoopとの組み合わせでも約3分の1に短縮します。
さらに、当社のパブリッククラウドサービス「FGCP/S5」、およびアマゾンウェブサービスの「Amazon Elastic Compute Cloud(以下、Amazon EC2)」、「Amazon Elastic MapReduce(以下、Amazon EMR)(注3)」上で本製品の動作を確認済みで、各クラウド基盤上にインストールして利用することができます。「FGCP/S5」では、月額のクラウドサービスとしても利用可能で、まずはクラウド環境で試行したり、スモールスタートでの運用が可能です。
[関連リンク] 「NetCOBOL」紹介サイト![]()
昨今、ビッグデータの利活用によるビジネスの変革が注目されるなか、大量データを高速処理するビッグデータ技術で、企業が抱えるバッチ処理の長時間化の問題を解決したいというニーズが高まっています。
本日販売開始する「NetCOBOL V10.5」は、アプリケーションを改修せずにCOBOLバッチ処理の高速化にHadoopを適用したいというお客様の要望に応えた製品です。COBOLとHadoopでは扱うデータ形式や処理方式に大きな差異がありますが、当社は独自のスマートソフトウェアテクノロジー(注4)によりこの差異を吸収し、COBOLバッチアプリケーションの処理時間の短縮を実現します。
本製品の特長
- COBOLバッチアプリケーションに手を入れずにHadoopで処理時間を大幅短縮
HadoopのフレームワークであるMapReduce(注5)とCOBOLのデータ形式の違いを、当社独自のデータ変換機能により吸収するため、COBOLのデータをMapReduceの入出力データとして利用できます。
また、Hadoopの基本は1つのファイルを使用する方式であり、COBOLバッチアプリケーションの複数ファイルを使用する方式と異なります。この違いを、複数入力変換機能により吸収するため、複数ファイルを使用するバッチアプリケーションでもHadoopを使えるようになります。
データ変換機能や複数入力変換機能など当社独自のスマートソフトウェアテクノロジーにより、COBOLのデータとアプリケーションに手を入れずに、再コンパイルのみでHadoopを適用できます。
当社の「Interstage Big Data Parallel Processing Server(注6)」と組み合わせれば、独自の分散ファイルシステムにより格納したデータに直接アクセスできるため、Apache Hadoopでは必要な入出力のデータ転送が不要となり、さらに処理時間を短縮できます。
マスタデータとトランザクションログなど、複数ファイルを入力してソート・マージ処理し、複数ファイルを出力するバッチアプリケーションで、特に適用効果を発揮します。例えば、128GBのデータを16多重で集計した場合の処理時間は、本製品と「Interstage Big Data Parallel Processing Server」の活用で従来のバッチ処理の約18分の1に大幅に短縮し、本製品とApache Hadoopの活用でも約3分の1に短縮しました。
なお、複数入力変換機能は、株式会社富士通研究所の技術(特許出願中:出願番号2012-224604)を製品化したものです。
- オンプレミスに加えクラウドでも利用できる
「NetCOBOL」は、日本のほか、北米を中心にグローバル約60ヶ国で利用されています。今回、オンプレミスでの利用に加え、当社のパブリッククラウドサービス「FGCP/S5」、アマゾンウェブサービス「Amazon EC2」と「Amazon EMR」でも本製品の動作を確認済みで、各クラウド基盤上にインストールして利用することができます。なお、「FGCP/S5」では、月額のオプションサービスとしても提供します。
「FGCP/S5」、「Amazon EC2」、「Amazon EMR」のいずれも、Apache Hadoopとの組み合わせで利用できます。
アマゾン データサービス ジャパン株式会社 代表取締役 長崎 忠雄 様からのコメント
富士通様が「Amazon Elastic MapReduce」(AWS上にホストされたApache Hadoopフレームワーク)に対応した「NetCOBOL V10.5」を発表されたことを歓迎します。今回のクラウドに対応したCOBOL新製品の発表と、このたびアマゾン ウェブ サービスの「AWS Partner Network」への富士通様のご加入により、今後より多くのお客様へ高い付加価値を提供するものと期待しております。
製品の販売価格、および出荷時期
| 製品名 | 販売価格(税別) | 出荷時期 | |
|---|---|---|---|
| プロダクト | NetCOBOL Enterprise Edition 開発・運用パッケージV10.5 (プロセッサライセンス) Linux版 |
168万円より | 2012年12月 |
| NetCOBOL Enterprise Edition 運用パッケージ V10.5 (プロセッサライセンス) Linux版 |
128万円より | ||
| クラウド | 「FGCP/S5」のオプションサービスとして以下を提供 ・NetCOBOL Enterprise Edition 開発・運用パッケージV10.5 ・NetCOBOL Enterprise Edition 運用パッケージ V10.5 |
8万4,000円(月額)より 6万4,000円(月額)より |
2013年2月 予定 |
- プロセッサライセンスは、マルチコアプロセッサの場合、コアの総数×特定の係数分のライセンスが必要です。
- クラウドサービスは、別途、基本サービス料金が必要です。
動作環境
| プラットフォーム | 動作OS |
|---|---|
| サーバ | Red Hat Enterprise Linux 6 (for Intel64) Red Hat Enterprise Linux 5 (for Intel64) Oracle Solaris 11 (2013年1月予定) Oracle Solaris 10 (2013年1月予定) Microsoft Windows Server 2012 Microsoft Windows Server 2008 R2 Microsoft Windows Server 2008 Microsoft Windows Server 2003 R2 Microsoft Windows Server 2003 |
| クライアント | Windows 8 Windows 7 Windows Vista Windows XP |
| クラウド | Fujitsu Global Cloud Platform FGCP/S5 Amazon Elastic Compute Cloud (2013年1月予定) Amazon Elastic MapReduce (2013年1月予定) |
- Hadoopが利用できるのは、Red Hat Enterprise Linux 6 (for Intel64)およびRed Hat Enterprise Linux 5 (for Intel64)です。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
- 注1 Apache Hadoop:
- Apache Software Foundation(ASF)が開発・公開している、大規模データを効率的に分散・並列処理するオープンソースソフトウェア。
- 注2 世界初:
- 2012年12月5日現在。当社調べ。
- 注3 Amazon Elastic MapReduce:
- 企業や研究者、データアナリスト、デベロッパーが容易かつコスト効率よく 莫大な量のデータを処理することができるようにするアマゾンのウェブサービス。「Amazon EC2」や「Amazon Simple Storage Service」のウェブスケールインフラストラクチャー上で稼働するホストHadoopフレームワークを役立たせる。
- 注4 スマートソフトウェアテクノロジー:
- ハードウェアやソフトウェアの状況を自ら判断し、より簡単・安心に使うために最適化を図る当社独自の技術。
- 注5 MapReduce:
- 大規模データの分散処理プログラミングモデルの1つ。またはこのモデルの実装を元にした分散処理フレームワーク。HadoopはMapReduceの実装の1つ。
- 注6 Interstage Big Data Parallel Processing Server:
- 最新のApache Hadoopをベースに当社独自の分散ファイルシステムを搭載し高信頼性、高性能を実現した並列分散処理ソフトウェア。本機能は「Interstage Big Data Parallel Processing Server V1.0.1」(2012年12月下旬出荷予定)より搭載。
関連リンク
本件に関するお問い合わせ
富士通コンタクトライン
![]() 0120-933-200
0120-933-200
受付時間: 9時~17時30分(土曜日・日曜日・祝日・年末年始を除く)
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。