PRESS RELEASE (技術)
2012年11月19日
株式会社富士通研究所
世界初!蓄積されたデータも流れるデータも高速に処理する
ビッグデータ向けストリーム集計技術を開発
株式会社富士通研究所(注1)は、世界で初めて、蓄積されたデータも流れるデータも高速に処理するビッグデータ向けストリーム集計技術を開発しました。
ビッグデータ処理では、大量のデータを高速に処理することが求められます。データを集計する際、集計期間が長くなるにつれ、扱うデータ量が増大し計算時間が延びるため、演算結果を頻繁に更新することが難しくなります。このように、集計期間を長くすることと、更新頻度を高めることの両立が困難でした。今回、時間によって変化する多様なデータに対して、データの読み直しや演算のやり直しを一切行うことなく演算結果を高速に返す、演算スナップショット管理技術を開発しました。これにより、集計期間が長く更新頻度が高い場合にも、従来に比べ100倍高速なデータ処理が可能になります。
本技術により、大量バッチ処理や、ストリームデータ処理などの既存業務の強化が見込まれます。さらに、気象分野で、これまで困難であった集中豪雨の詳細なエリア提示が可能になり、今後の予報に役立てるなど、長期間データのリアルタイム処理が不可欠な新たな事業領域への展開を図ることが期待されます。
本技術の詳細は、11月30日(金曜日)に東海大学高輪キャンパスで開催される電子情報通信学会ソフトウェアインタプライズモデリング研究会(SWIM)ワークショップ特別講演にて発表します。
開発の背景
近年、高度なICT技術を活用して、大量のデータを高速に処理することで競争優位性を高めることに、多くの企業が関心を寄せています。たとえば、取引データを定期的にまとめて一括処理を行う大量バッチ処理や、値動きに基づき株取引をリアルタイムに行うストリームデータ処理などがあります。
これらのデータ処理には集計演算が不可欠ですが、大量バッチ処理とストリーム処理では、集計期間や更新頻度に違いがあります。通常、集計期間は、スループットを重視する大量バッチ処理で数週間から数か月単位、レスポンスを重視するストリームデータ処理では数秒から数分単位であり、更新期間もほぼこれに準じます。
課題
大量バッチ処理とストリーム処理では重視する性能が異なるため、用途に応じて使い分ける必要があります。
- 従来の大量バッチ処理技術
蓄積されたデータを大量に扱うため、処理のたびにすべて読み直す必要が生じ、演算結果を得るまでの遅延時間が長いという問題があります。
- 従来のストリーム処理技術
時々刻々と流れるデータをウィンドウと呼ばれるバッファに保持するため、処理のたびに読み直しは発生しませんが、演算の種類によっては、演算結果を得るためにウィンドウ内のすべてのデータにアクセスする必要があります。そのため、ウィンドウの長さに比例して、1回あたりの演算時間が長くなり、レスポンスが悪くなるという問題があります。
過去(蓄積されたデータ)と現在(流れるデータ)の両方を同時に扱う場合、これらの既存技術では、上記課題の通り、集計期間を長くすることと、更新頻度を高めることの両立が困難でした。
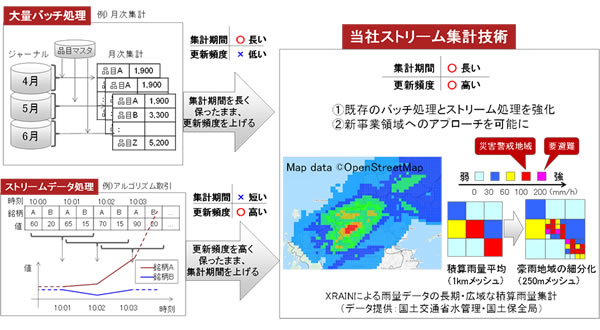
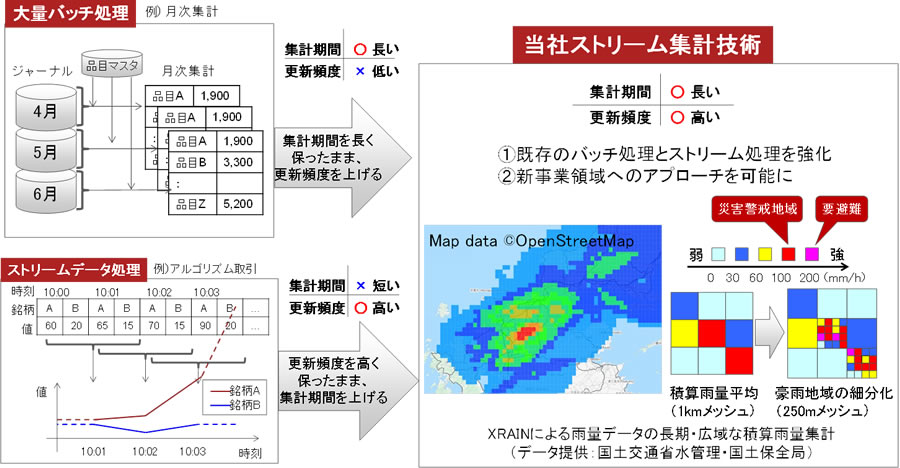
図1 従来技術と今回開発した技術の位置づけ
拡大イメージ
{kind=link}
開発した技術
今回、以下の2つの技術の組み合わせにより、長期間かつ更新頻度の高いデータに対する高速なストリーム集計技術を開発しました(図2)。
- 高速パターン照合技術
入力されるストリームデータの中から、必要な項目を無駄なく直接取り出す技術です。通常は、まず入力データの構造解析を行い、メモリ上に入力データの全項目を一旦蓄積します。その後、集計に必要な項目を取り出すための項目抽出処理を行いデータを取り出します。このように構造解析、項目抽出の2段階の処理が必要となります。これに対し本技術では、パターン照合により取り出すべき項目の出現位置を特定し、不要な項目を読み飛ばし、必要な項目のみを直接取り出すため高速処理が可能です。また、パターン照合は柔軟であり、定型データ(CSVデータなど)に加えて、繰り返しや階層構造を含む非定型データ(XMLデータなど)にも対応しています。
- 演算スナップショット管理技術
時間によって変化する多様なデータに対して、データの読み直しや演算のやり直しを一切行うことなく、演算結果を高速に返す技術です。入力されるストリームデータに対し、通常は時系列順にメモリ上にデータを保持しますが、本技術では、あらかじめ決められた手順に従いソートなど必要な演算を行いながらデータを保持します。集計結果をすぐに取り出せるように常に演算された状態(演算スナップショット)で管理されているため、合計値や平均値だけでなく、最小・最大値や中間値であっても全データを用いて集計をやり直す必要がありません。そのため集計期間(ウィンドウ長)に依存しない高速なレスポンスを実現できます。
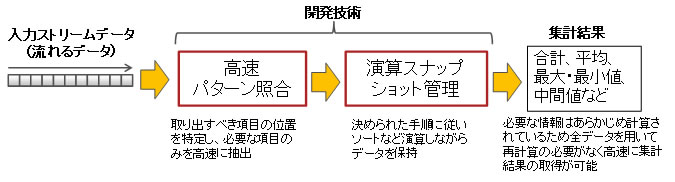
図2 ストリーム集計の流れと開発技術
効果
集計結果を得るためのレスポンス時間は、集計期間(ウィンドウ長)に50万件のデータがある場合、代表的なオープンソースの複合イベント処理(CEP: Complex Event Processing)エンジンに比べて、約100倍以上高速で、かつウィンドウ長によらずレスポンス時間が一定であることを確認しました(図3)。
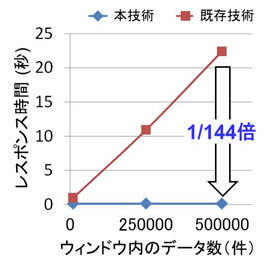
図3 従来技術とのレスポンス時間比較
本技術は、高精度センサーデータの活用への応用が期待されます。国土交通省水管理・国土保全局からXRAINによる雨量データ(注2)を提供いただき、技術検証を行いました。関西地域の50万地点を対象に、数時間の積算雨量を集計する場合、数分ごとに約1億レコードのウィンドウを処理する必要があります。これだけ広範囲のデータを、更新間隔以内に、集計期間に左右されることなく実行し、雨域のスムーズな移動を再現できることを確認しました(図1)。積算雨量は、瞬間雨量よりも災害との関係が強く、集中豪雨に伴う災害警戒地域を即座に検出することが可能です。
また、既存のバッチ処理とストリーム処理への応用も期待されます。売上データ集計のリアルタイム性を向上することで、生産・在庫管理などをさらに強化することが可能です。
今後
2013年度に富士通株式会社の「Big Data Platform」や「Big Data Middleware」製品への搭載を目指します。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
- 注1 株式会社富士通研究所:
- 代表取締役社長 富田達夫、本社 神奈川県川崎市。
- 注2 XRAINによる雨量データ:
- 国土交通省XバンドMPレーダネットワークによる雨量データ。250メートルごとに1分間隔で計測された広域にわたる雨量データで、集中豪雨のような極端で局所的な気象現象まで詳細に記録。
本件に関するお問い合わせ
株式会社富士通研究所
ソフトウェアシステム研究所 インテリジェントテクノロジ研究部
![]() 044-754-2652(直通)
044-754-2652(直通)
![]() pr-stream-agg@ml.labs.fujitsu.com
pr-stream-agg@ml.labs.fujitsu.com
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。