PRESS RELEASE
2012年4月5日
株式会社富士通研究所
ビッグデータの分単位での活用が可能に!
ディスクアクセスを大幅に削減する並列データ処理技術を開発
株式会社富士通研究所(注1)は、ビッグデータと呼ばれる蓄積された大量のデータ、および継続的に入ってくる新しいデータを効率よく処理することで、これらデータを分単位で活用可能にする並列分散データ処理技術を開発しました。
センサーデータや人の位置情報など多種で大量なデータが増え続けており、これらのビッグデータを高速に分析して活用するために、さまざまなデータ処理技術が開発されています。高速性能を優先する場合はデータをメモリ上で処理する方法が適していますが、大容量のデータに対応するためにはメモリに収まりきらないためディスクベースの技術が用いられるのが一般的です。しかしディスクベースの技術では、新しく到着したデータをすばやく分析結果に反映させようとするとディスクの読み書きが大量に発生し、データの到着ペースに分析処理が追いつかなくなるという課題がありました。
今回、データの読み書きの傾向に合わせてディスクのデータを動的に再配置することで、ディスクへの読み書きを従来の約1/10(注2)に削減する技術を開発しました。これにより、従来、新しいデータを分析結果に反映するまでに数時間かかっていたものが数分で可能となります。つまり、従来は難しかった、「大量」と「即応性」を両立させることができるようになります。
本技術は、あらゆる場所で的確なサービスを提供するヒューマンセントリック・コンピューティングを支える技術の一つとして活用していきます。
開発の背景
近年、センサーデータや人の位置情報などの時系列データを代表とする、多種で大量なデータが飛躍的に増え続けています。これら「ビッグデータ」と呼ばれるものから、価値ある情報をいかにすばやく引き出し、各種のナビゲーションなどに役立てられるかが求められています。
このようなビッグデータを活用するため、すでにさまざまなデータ処理技術が開発されています(図1)。たとえば、大量データを処理する技術として Hadoop(注3)などの並列バッチ処理(注4)が注目されています。並列バッチ処理では、大量データを分割して複数のサーバで高速に処理できます。
一方、到着したデータをリアルタイムに処理する複合イベント処理技術(注5)などの技術も注目されています。これらは処理をメモリ上で行うことで非常に高速な応答が得られます。
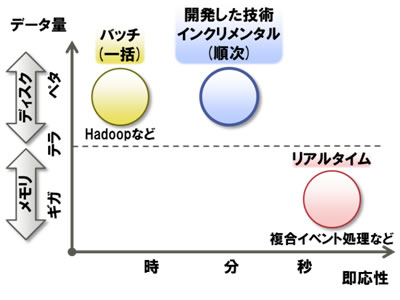
図1 大量データ向けの既存技術と開発した技術の位置づけ
課題
より大量のデータから価値ある情報をよりすばやく引き出すためには、ディスクベースでかつ高速に分析結果を得られるデータ処理技術が必要です。ディスクベースのデータ処理の方式はバッチ(一括)方式とインクリメンタル(順次)方式がありますが、どちらも分析結果をすばやく得ること(即応性)に課題がありました(図2)。
バッチ方式では分析対象データをいったん蓄積してから一括的に処理するため、新しい情報が分析結果に反映され活用できるようになるまでに一定の時間差が生じてしまいます。
また、インクリメンタル方式では新着データをその都度、順次に処理し、分析結果を直接アップデートするため、ディスクへのアクセスが多発します。そこが分析処理全体のボトルネックとなり、データの到着ペースに分析処理が追いつかなくなってしまいます。したがって、新しいデータをすばやく分析結果に反映させながら、ディスクの読み書きの回数を抑えることが課題となっていました。
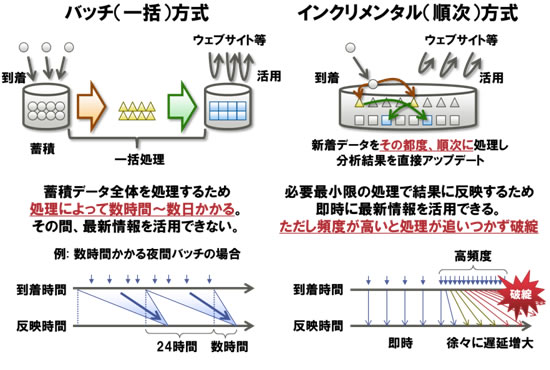
図2 バッチ(一括)方式とインクリメンタル(順次)方式の課題
開発した技術
今回、ディスクの読み書きの回数を大幅に削減する「適応的データ局所化技術」を開発し、インクリメンタル方式の並列分散データ処理ミドルウェアを実現しました。
適応的データ局所化では以下のステップでデータ配置を最適化します(図3)。
- アクセス履歴を記録
連続してアクセスされたデータの組を記録します。
- 最適な配置を計算
1.の記録に基づき、連続してアクセスされる傾向の高いデータの組を、グループ化します。
- 動的にデータを再配置
2.に計算に基づき、グループに属するデータを、ディスク上の一か所に固めて配置します。
これによって、多数のランダムアクセスではなく少数の連続アクセスのみで必要なデータを取得することが可能となり、分散処理系全体のスループットが大幅に向上します。また、データアクセスを観測して自動的に判断することで、あらかじめ予想しにくい社会システムのデータ特性にも徐々に順応することができます。
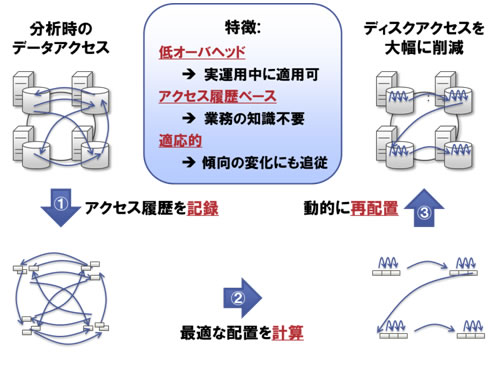
図3 適応的データ局所化技術
効果
本技術により、大量データの分析処理において、新しいデータが届くそばからインクリメンタルに処理して、すばやく最新の分析結果を得ることが可能になります。
本技術を電子商取引で行われるリコメンデーションのための分析処理の一部に適用したところ、従来技術に比べてディスクの読み書きの回数を約 1/10 に削減できることを確認しました。これにより、従来バッチ方式で処理されていたような大量データの分析処理にインクリメンタル方式を適用することができ、新しいデータが分析結果に反映されて活用できるまでの遅れを大幅に削減することが可能になりました。バッチ方式では数時間かかるために夜間バッチなどで実行されていた分析処理に本技術を適用すると、数分程度の遅延で分析結果を活用できるようになります(図4)。
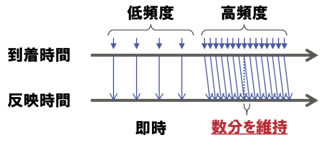
図4 本技術の効果
今後
富士通研究所では、本技術のさらなる性能向上および実証実験を進め、2013年度中の実製品・サービスへの適用を目指します。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
- 注1 株式会社富士通研究所:
- 代表取締役社長 富田達夫、本社 神奈川県川崎市
- 注2 ディスクへの読み書きを従来の約1/10に削減:
- リコメンデーションのための分析処理におけるディスクアクセス数を従来技術と比較。
- 注3 Hadoop:
- Apache Hadoop。Apache Software Foundation(ASF)が開発・公開している、大規模データを効率的に分散・並列処理するオープンソースソフトウェア。
- 注4 並列バッチ処理:
- 蓄積しておいたデータに対し、分析などを一括して並列で実行する処理。
- 注5 複合イベント処理技術:
- Complex Event Processing (CEP)。ビッグデータから価値のある情報をリアルタイムに引き出すための手法。あらかじめ定義したルール(クエリ)にもとづいた処理をメモリ上で行うことでリアルタイム性を実現。
本件に関するお問い合わせ
株式会社富士通研究所
クラウドコンピューティング研究センター
![]() 044-754-2575
044-754-2575
![]() aidp@ml.labs.fujitsu.com
aidp@ml.labs.fujitsu.com
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。