PRESS RELEASE (技術)
2012年3月13日
株式会社富士通研究所
業界初!ビッグデータから必要なデータをクラウドに効率的に収集する分散処理技術を開発
公衆網に流れるデータ量を従来の1/100に削減し、通信コストを削減
株式会社富士通研究所(注1)は、クラウドに収集される大量の実世界のデータを、ネットワークを中継するゲートウェイを介して効率的に収集する分散処理技術の開発に業界で初めて成功しました。現在、ヒトの現在地や健康状態、モノの稼働状況など、実世界のさまざまなデータを大量にクラウドに収集して活用するクラウドサービスが拡大しており、データ収集に伴う通信量の増加が大きな課題となっています。今回、クラウド上の処理の一部をゲートウェイに最適に分散配置するアルゴリズムを新たに開発しました。この技術を使って、ゲートウェイ上でデータ処理を行いビッグデータから必要なデータを効率的にクラウドに収集することで、通信量を従来の約1/100(注2) に削減することが可能になります。
これにより、大量の実世界データを通信コストを抑えながらクラウド側で容易に活用できるようになるため、人や環境の状態に応じたきめ細かいサービスの提供を通じて、ヒューマンセントリックでインテリジェントな社会の実現への貢献が期待されます。
開発の背景
近年、デバイスや端末の小型化、通信技術の高度化により、ネットワークに接続されるさまざまな機器やセンサーを通じて、ビッグデータを収集し活用するクラウドサービスが実現されつつあります。実世界で発生する大量のデータをクラウド上に集めることで、これまで見えなかった新しい知見を得て、それを社会に新しい価値として還元することができるようになってきました。たとえば、電力ネットワーク制御などの社会インフラの最適化や、M2M(Machine to Machine:機械と機械をつなぐ通信の利用方法)による機器の予防保守などが挙げられます。
課題
大量の機器がネットワークに接続されることによる通信量の増加に伴い、クラウドや通信網の設備増強が必要となり、通信コストの増加をまねくことが大きな課題になっています。近年のスマートフォンの普及や、今後、ヒトだけでなく大量の機器がネットワークにつながるようになると、通信量はますます増加することが予想され、通信量の削減技術が強く求められていました。
課題解決のアプローチ
多くの場合、センサーや機器から発生するデータは、データをそのままではなく統計処理や分析処理が施されて利用されます。このため、ある程度の処理能力を持つゲートウェイをデータの発生場所に設置し、できるだけデータの発生源の近くでフィルタリングや統計処理などの前処理を行い、処理結果だけをクラウドに上げることで通信コストを削減するアプローチが有効です。
たとえば、図1の消費電力見える化の例では、各事業所単位で集められる分電盤や電源タップからの生データ(電力データ) は、本社経営者に対しては会社単位の集計データに加工して提示されます。そこで、各事業所のゲートウェイでこれらの集計処理を事前に行い、集計結果だけをクラウドに送ることで、送信データ量を抑えることができます。また、クラウドに送らなかった生データは、クラウド側で本当に必要になった時に初めて圧縮送信することで、生データを個別に送るよりもデータ量を削減することができます。
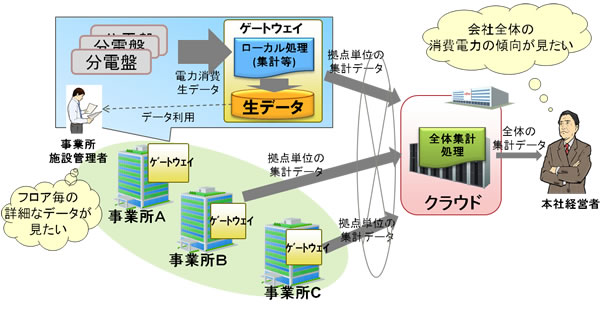
図1 ゲートウェイ・クラウド間での分散処理(消費電力見える化の例)
開発した技術
今回、上記アプローチに基づいてゲートウェイ上にクラウドの処理の一部を分散実行させることで、通信量を削減する分散処理技術を開発しました。開発した技術の特徴は以下の通りです。
- 分散処理運用フレームワーク技術
クラウド上の処理の一部をゲートウェイ側で分散処理する場合、これまではクラウド側のどの処理をどのゲートウェイで実行させるとデータ量の削減に効果があるかを運用管理者が判断する必要がありました。しかし、ゲートウェイの数は接続するセンサーの数に応じて増設・撤去され、またそれに応じて接続構成も変更されるため、運用管理者が毎回、システムを再設計する必要があり、運用負担が大きくなるという課題がありました。
そこで、今回、実行先のゲートウェイを自動的に見つけ、処理プログラムの配備・実行を支援する運用フレームワークを開発しました(図2)。
運用管理者は、データ処理プログラムを集計処理やフィルタリング、平均などの小さな処理単位の繋がり(フロー)として定義するとともに、センサー/機器・ゲートウェイ・クラウドまでの通信経路を示したネットワークトポロジーを定義します。フレームワークは、この処理フローとネットワークトポロジーの二つの情報をもとに、処理フロー内の個々の処理がどのゲートウェイで実行可能になるかを解析し、通信量が最も小さくなるゲートウェイ配備の組み合わせを生成します。また、運用中に接続構成が変化した場合でも、新しいネットワークトポロジーをフレームワークに再定義することで、そのネットワークトポロジーに応じたゲートウェイ配備に再構成することができるため、最適な分散処理を実現することができます。
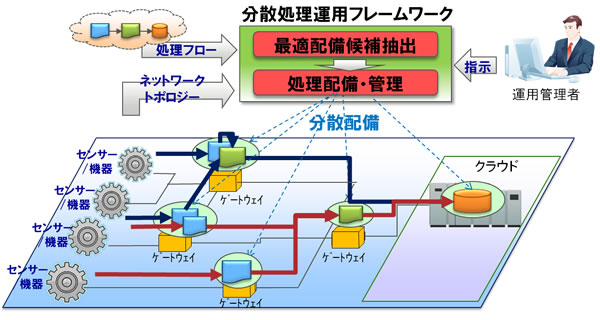
図2 分散処理運用フレームワークの概要 - 集約キーによる処理フローの分割と最適配備候補の抽出技術
処理フローを構成する平均や集計などの処理は、複数のセンサーデータのまとまりに対して実行されるため、それらのセンサーデータが物理的に一か所に集まるポイントで処理を実行することが通信量の削減に効果的です。一方、平均や集計などの処理は、「部署や会社単位での平均」など、論理的なデータのまとまりへの処理も多く、センサーデータそのものだけでなくそのセンサーデータが持つ論理的な意味を加味して配備先を決定する必要があります。そこで、今回、「部署」や「会社」といった各処理がデータをグルーピングする際の分類キー(集約キー)と、「部署」や「会社」の値とセンサーとの論理関係をもとに、処理単位とその処理が対象とするセンサー群を抽出し、処理単位ごとの最適な実行先のゲートウェイを効率的に見つけ出す方法を開発しました。
図3の例では、以下の流れで配備先候補の抽出処理が行われます。
- 処理フローの解析
処理フローの集約キーが解析され、センサーと集約キーの値との論理関係から、部署単位の平均処理4つと会社単位の合計処理2つが、処理単位として抽出されるとともに、各処理単位が入力とするセンサーが特定されます。
- 集約キー値の収集経路の解析と配備候補ゲートウェイの選択
集約キーの値に対応づいたセンサーデータが、ネットワークトポロジーのどの経路を経由するかを追跡することで、XX商事の合計処理がゲートウェイIやゲートウェイIIでは実行できないことが判定され、ゲートウェイIII、およびゲートウェイ・クラウドが配備候補として抽出されます。他の処理単位に対しても同様に配備候補が選択されます。
- 最適な配備組合せの作成
配備候補ゲートウェイの組合せの中から、最も通信量が小さくなる結果が開発者に提示されます。開発者が候補の中から配備先を選択することで、ゲートウェイに実際の処理が配備され実行されます。
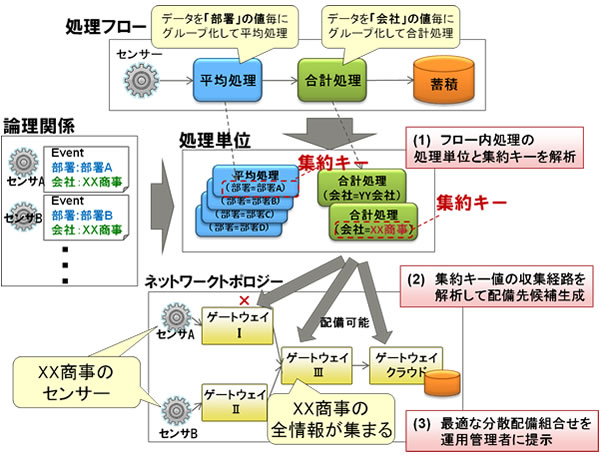
図3 最適配備候補抽出技術の処理の流れ - 処理フローの解析
効果
今回開発した技術を用いることで、ビッグデータを活用するシステムの運用管理者はゲートウェイを意識せずにクラウドでの処理として記述した処理を自動的に分散処理させることができ、さらに、通信量を従来の約1/100に削減することが可能になります。これにより、大量の実世界データを活用するクラウドサービスを、通信コストを抑えながら運用することができるため、人や環境の状態に応じたきめ細かいサービスの提供を通じて、ヒューマンセントリックでインテリジェントな社会の実現への貢献が期待されます
今後
富士通研究所では、情報ゲートウェイ技術の配備候補抽出アルゴリズムの高速化を進め、2013年度中の実用化を目指します。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
関連リンク
本件に関するお問い合わせ
株式会社富士通研究所
ヒューマンセントリックコンピューティング研究所 スマートコミュニケーション研究部
![]() 044-754-2667(直通)
044-754-2667(直通)
![]() proc-dist@ml.labs.fujitsu.com
proc-dist@ml.labs.fujitsu.com
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。