
- > プレスリリース >
PRESS RELEASE (技術)
2006-0017
2006年1月27日
株式会社富士通研究所
業界トップのe-文書対応カラー文書認識技術
~JPEG圧縮による画像劣化や多様な色使いに対応した
ハイブリッド型テキスト領域抽出技術の開発に成功~
株式会社富士通研究所(注1)は、JPEG形式で圧縮し画像劣化したカラー文書画像や、多様な色使いが用いられたカラー文書画像から、高精度にテキストの含まれる領域を抽出するハイブリッド型テキスト領域抽出技術の開発に成功しました。
今回開発した技術により、オフィスにおいて電子化した紙文書を低コストかつ高精度で検索することが可能になります。
開発の背景
2005年春施行のe-文書法により、オフィスにおける膨大な紙文書を電子化し、それに含まれる文字で検索する機能の需要が高まってきています。紙文書の検索を可能にするには、JPEG形式で圧縮された紙のカラー文書から、1)テキストが含まれる領域を抽出し、2)テキスト中の文字を認識する必要があります。(図1)しかし、従来はJPEG圧縮による画質劣化や多様な色使いのため、紙のカラー文書に含まれるテキスト領域を高精度で抽出することが困難でした。
|

課題
JPEG形式で圧縮されたカラー文書は、画質の劣化によりテキスト領域周辺に色むらが発生します。従来のテキスト領域抽出技術では、色むらをテキストと誤ることでテキスト同士やテキストと図が接触して、テキスト領域を正しく抽出できませんでした。また、白抜き文字に対してテキスト周辺の背景を誤ってテキスト領域として抽出してしまうなど、多様な色使いのレイアウトに対応できないという問題がありました。
開発した技術
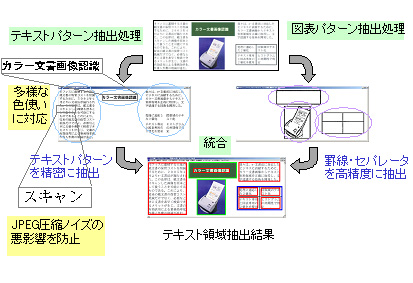
今回開発したハイブリッド型テキスト領域抽出技術は、以下のようにテキストパターン抽出処理と図表パターン抽出処理を相補的に組み合わせることで、高精度なテキスト領域抽出を可能とします。
テキストパターン抽出処理は、カラー画像における色変化の大きいところを検出して文字輪郭領域を推定することにより、文字色を適応的に判定してテキストパターンを抽出します。これにより、多様な色使いのレイアウトに対応可能になるとともに、文字輪郭領域以外からの色むらノイズの発生を防ぎ、テキスト領域を精密に抽出することができます。
一方、図表パターン抽出処理では、罫線やレイアウト上の区切り線(セパレータ)の連結性を考慮して抽出することにより、従来はとぎれとぎれになっていた罫線やセパレータを高精度に抽出し、罫線やセパレータに囲まれたテキストパターンの含まれる領域候補を絞り込むことができます。
テキストパターン抽出処理により抽出されるテキストパターンと、図表パターン抽出処理によって得られるテキストの存在領域とを組み合わせることにより、文書に含まれるテキスト領域を高精度に抽出します。(特許出願済み)(図2)
|
効果
テキスト領域の抽出エラーを当社従来技術比で約6割削減して、他社を凌ぐ業界トップ(注2)のテキスト領域抽出率96%を達成しました。これにより、トータルな検索用テキスト抽出の精度が向上し、文書に対して正確なキーワードを付与する作業のコストを従来比で約37%削減できました。
今後
本技術を当社スキャナ製品に搭載し、提供していきます。
以上
注釈
技術に関するお問い合わせ
株式会社富士通研究所 ITコア研究所 言語・メディア研究部
電話: 044-754-2678(直通)
E-mail: lm-pr@ml.labs.fujitsu.com
プレスリリースに記載された製品の価格、仕様、サービス内容、お問い合わせ先などは、発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。
![]()